扩散模型(diffusion)论文笔记(2023.3)
HS-Diffusion:学习一种语义引导的人头交换扩散模型
HS-Diffusion:
Learning a Semantic-Guided Diffusion Model for Head Swapping
Qinghe Wang等 字节&天大
针对问题
基于图像的 人头交换 任务:将一个源头部完美地缝合到另一个源身体上。
这项任务面临两大挑战:
在生成无缝过渡区域的同时,从各种来源保留头部和身体。
迄今为止没有配对头交换数据集和基准数据集。
提出方法
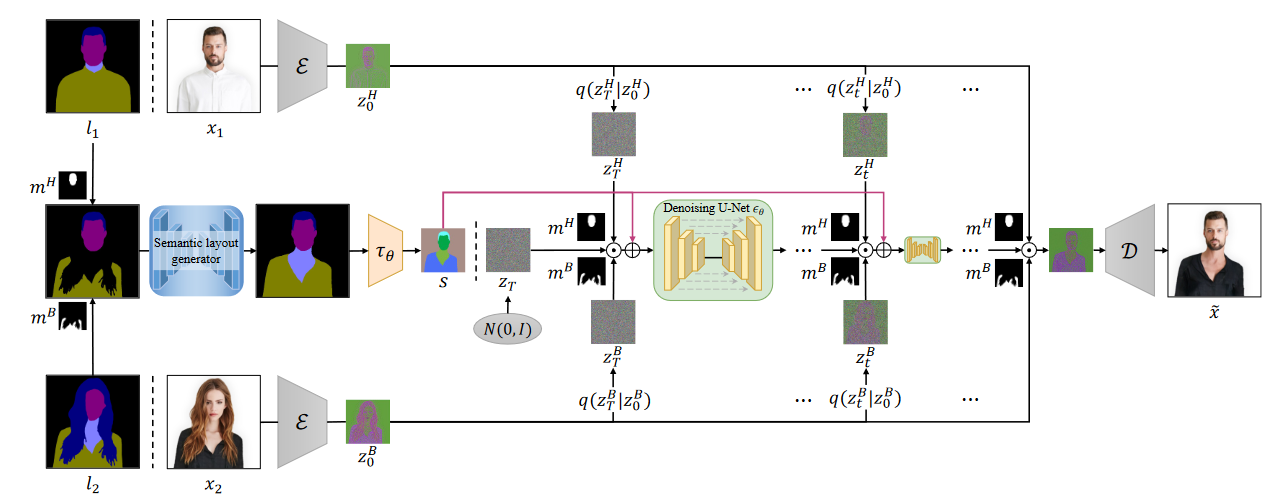
为了让过渡区域体现无缝性,我们分别训练了一个 语义引导的潜在扩散模型( SG-LDM )和一个 语义布局生成器。基于图像的头部交换总结为以下步骤:
( i ) 将语义布局
( ii ) 通过语义布局生成器绘制过渡区域。
( iii ) 从
( iv ) 在每个去噪步骤中,将混合噪声与语义潜在表示
( v )利用SG - LDM从
语义引导的LDM(SG-LDM)
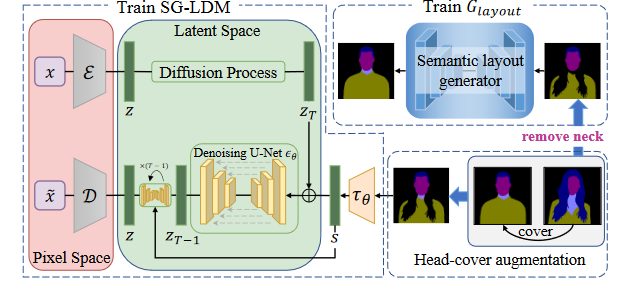
对DM的理论还不甚了解,先通过此论文的描述学习一二。
潜在扩散模型(LDM)可以训练生成以语义布局为条件指导的图像( SGLDM )。
SG - LDM由3个部分组成: * 预训练自编码器
更具体地说,编码器
通过高质量的重构,扩散过程可以工作在低维的隐空间中。
当
Head_cover增强策略
为了模拟头像交换中头发遮挡颈部和身体的情况,设计了Head_cover增强策略,分别训练SG - LDM和语义布局生成器。
从训练数据集中随机采样两个半身语义布局
语义布局生成器
为了给SG - LDM换头提供合理的语义指导,我们设计了一个嵌套U -
Net架构的语义布局生成器
基于
颈部对齐技巧
测量
结论
本文提出了基于图像的头部交换框架,该框架由 语义引导的潜在扩散模型 和 语义布局生成器组成。
我们以自监督的方式用提出的Head-cover增强来训练我们的框架。并且所提出的颈部对齐技巧将源头部对齐到下游模型可以产生更几何逼真的头部交换结果的位置。
此外,我们构建了一个新的基于图像的头部交换基准,并提出了FID ( Mask - FID和FocalFID)的两个评价指标的改进以进一步比较。
T2I
- Adapter:挖掘文本-图像扩散模型的可控性
T2I-Adapter: Learning
Adapters to Dig out More Controllable Ability for Text-to-Image
Diffusion Models
Chong Mou等 清深&腾讯
针对问题
虽然文本-图像生成可以达到很好的合成质量,但严重依赖于准确的 提示,生成管道也缺乏用户灵活 控制能力,无法指导生成图像的结构/风格以准确地实现用户的想法。
提出方法
初步:稳定扩散
该方法基于目前SOTA T2I扩散模型(稳定扩散模型,SD)。SD是一个两阶段扩散模型,包含一个自编码器和一个UNet去噪器。
第一阶段,SD训练了一个自编码器,该自编码器可以将自然图像转换到潜在空间,然后进行重建。
第二阶段,SD训练一个改进的UNet去噪器,直接在隐空间中进行去噪。
在推理过程中,输入隐映射
在条件部分,SD利用预训练的CLIP文本编码器(CLIP Text
Encoder)将文本输入作为嵌入序列
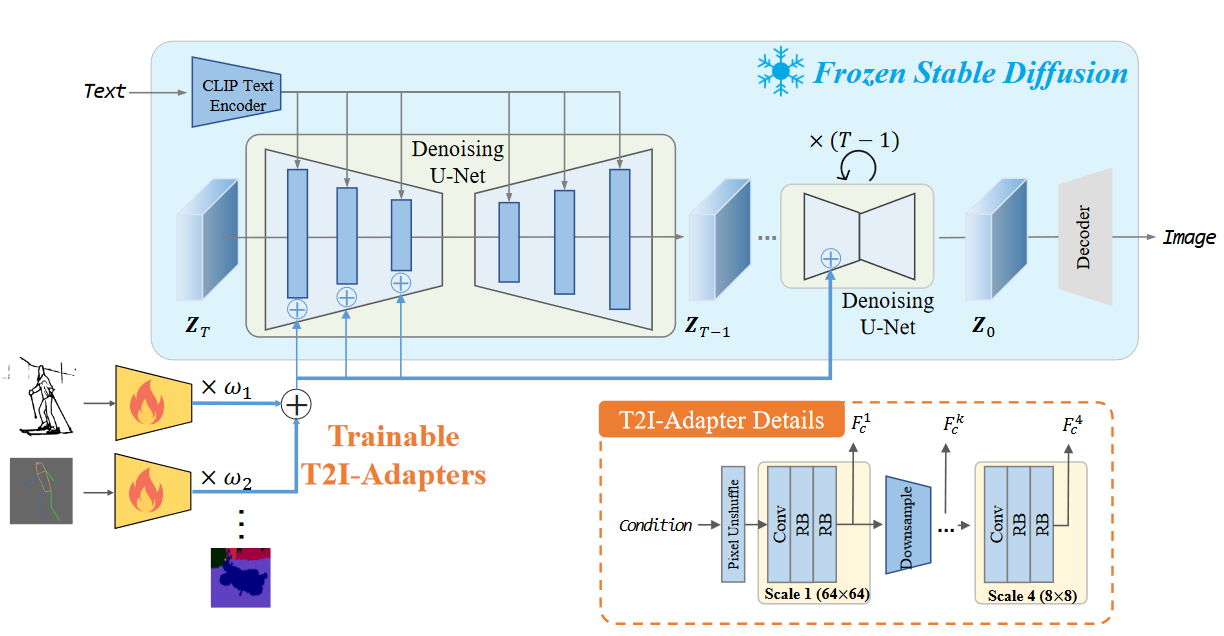
T2I-Adapter
文章提出学习简单的小型T2I适配器来对齐T2I模型中的内部知识和外部控制信号,同时冻结原始的大型T2I模型。Adapter用于从不同condition中提取指导。预训练的扩散模型具有固定的参数,根据文本条件和条件生成自然图像。
T2I-Adapter由4个特征提取模块和3个下采样模块组成以改变特征分辨率。原始条件输入的分辨率为512
× 512,利用 像素逆混洗 将其下采样为64 ×
64。在每个block中,利用一个卷积层和两个残差块( RB )从不同分辨率(即64 ×
64、32 × 32、16 × 16、8 × 8)的输入条件中提取结构特征
模型优化在优化过程中,我们固定SD中的参数,只优化T2I适配器。优化过程与SD类似。
结论
我们提出学习简单且小的T2I - Adapter来将T2I模型中的内部知识与外部控制信号对齐,同时冻结原始的大T2I模型。这样就可以根据不同的条件训练各种适配器,实现丰富的控制和编辑效果。此外,所提出的T2I - Adapter具有可组合性和泛化能力等具有实用价值的优良特性。
Collage Diffusion
拼贴扩散
Collage Diffusion
斯坦福大学
针对问题
对具有多个对象的场景的图像输出进行精确控制。
用户通过定义拼贴来控制图像生成。拼贴(collage):成对的文本提示与有序的图层序列,其中每图层都定义为 RGBA 图像和相应的文本提示。
主要挑战:协调输入拼贴,同时限制某些对象属性(空间位置、视觉特征)的变化,但允许其他对象属性(方向、光照、透视、遮挡)的变化。
目标:生成用户所需场景组成的高质量全局协调图像,无论是在空间保真度方面,即保留所需对象的位置和大小,还是在外观保真度上,即保留对象的视觉特征。
问题定义
拼贴collage
全拼贴文本字符串
,描述要生成的整个图像(“一个有米饭、毛豆、生姜和寿司的便当盒”) n 个拼贴图层的序列
,从后到前排序, 具有以下属性: RGBA 图像
(寿司的 alpha-mask输入图像),具有 alpha 层 . 描述图层的文本字符串
,它是 的子串(“寿司”).
给定拼贴
全局协调性。
具有真实图像的一致性。输出图像在场景对象之间具有一致的透视、光照和遮挡。 空间保真度。
符合拼贴中指定的 场景构图。对于任意图层 ,图层文本 描述的对象应当生成在 的适当区域。 外观保真度。对于所有图层
,除了匹配图层文本 之外,描述图层内容的 区域与 共享视觉特征。
基于先前基于扩散的技术来约束生成图像的空间布局和单个对象的外观,允许图像的所有其他属性在协调过程中发生变化。
提出方法
全局图像协调
先说说SDEdit。
Meng, C., Song, Y., Song, J., Wu, J., Zhu, J.-Y., and Ermon, S. Sdedit: Image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021).
如果不用拼贴的方式,只是提供
它通过将标准差为
问题:一些对象没有在适当的位置生成,并且视觉特征的输入图像未保留。
而拼贴输入的 文本信息 和 视觉信息 对应于图像的每个区域,提供了对生成图像的各个组件进行更细粒度控制所需的输入。
空间保真度:使用 交叉注意机制
为了在所需位置生成具有所需对象的图像,Collage Diffusion 修改了文本条件 U-Net 模型 Dθ 中的文本-图像交叉注意力。
先说明两个概念:
全局token:开始标记、结束标记、输入字符串中的几个单词和填充标记这些 缺乏对特定区域影响的token。
图层token:特定于某个图层的token。
Collage Diffusion 根据相应图层的可见位置 限制 层token 对图像区域的影响,从而对图像生成过程进行约束。
像素坐标(a,b)处的可见图层:在像素坐标 (a, b) 处具有非零 alpha 的 n 个图层中最高的图层。
注意力图
负注意力图
外观保真度:使用 文本反转
通常情况下,图层的图层文本
为此,Collage Diffusion 采用了一种类似于文本反转的方法:
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A. H., Chechik, G., and CohenOr, D. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022).
从每个图层 学习出 修饰符token
目标图像
用每层噪声 控制协调保真度权衡
图层输入允许用户在每个对象的基础上控制协调保真度权衡,用户可以指定在每个图层的协调过程中添加的噪声量。
用户为每图层
为了根据 h 将不同级别的噪声添加到图像的不同区域,控制输入图像每图层的真实度 - 保真度权衡,本文修改了扩散过程:
其中
编辑生成图像中的单个图层
对于由大量对象组成的场景,可能很难通过大型输出图库来查找场景中所有对象看起来都完全符合要求的实例。但是用户可以简单地选择其中大部分对象看起来都符合要求的图像,然后通过为剩余的对象生成替代可能,从而改进图像。
图层噪声控制使用户能够通过将应保持不变的层的噪声级别设置为 t = 0 来保持输入拼贴画的一部分“固定”。使用 Collage Diffusion 生成图像后,可以通过创建新的两层拼贴来编辑单个对象,其中生成的图像是背景层,要重新生成的对象是前景层。为背景层设置每层噪声 t = 0,为前景层设置任意期望的噪声水平,为前景层生成各种可能性,并与固定背景层协调和组合。
结论
Collage Diffusion 以拼贴的形式引入了一种新的控制形式,即表达用户所需空间布局以及生成图像中各个对象的视觉特征细节的图像组合。 Collage Diffusion 采用算法技术来限制生成对象的空间布局以及这些对象的视觉特征,使用户能够利用简单而传统的拼贴艺术技术生成视觉上引人注目的图像。
LDM:基于潜在扩散模型的高分辨率图像合成
High-Resolution
Image Synthesis with Latent Diffusion Models
CVPR 2022.6
针对问题
首先,训练一般 DM 模型需要大量的计算资源,只能用于该领域的一小部分。其次,评估一个已经训练好的模型在时间和内存上也很昂贵,因为相同的模型架构必须按顺序运行大量步骤。因此,本文旨在不损害 DM 性能的情况下减少 DM 的计算需求。
提出方法
明确分离压缩与生成学习阶段。利用自动编码模型学习一个空间,该空间在感知上等同于图像空间,但显着降低了计算复杂度。
感知图像压缩
感知压缩模型由一个自动编码器组成,该自动编码器通过 感知损失 和 基于补丁的对抗目标 的组合进行训练。这确保了通过 加强局部真实性 将重建限制在图像流形中,并避免仅依赖像素空间损失(例如 L2 或 L1 目标)引入的模糊。
更准确地说,给定 RGB 空间中的图像
潜在扩散模型
扩散模型是概率模型,旨在通过逐渐对正态分布变量进行去噪来学习数据分布
潜在表示的生成模型。 通过训练得到的由
模型的网络主干
调节机制
我们通过使用交叉注意力机制增强其底层 UNet 主干,将 DM
转变为更灵活的条件图像生成器,这对于学习各种输入模式的基于注意力的模型是有效的。引入了一个领域特定编码器
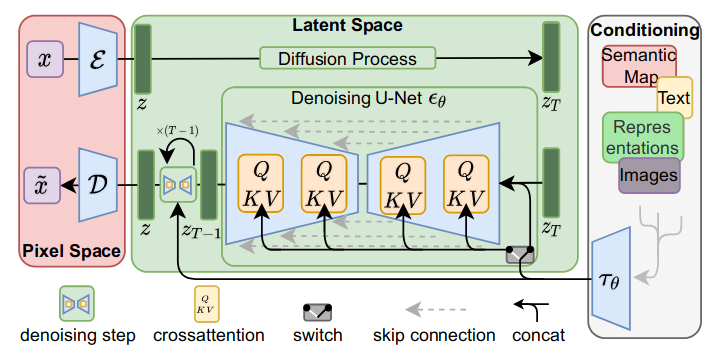
通过以下方式学习条件 LDM:
结论
潜在扩散模型可以在不降低质量的情况下显著提高去噪扩散模型的训练和采样效率。
扩散自动编码器:有意义和可解码的表示
Diffusion
Autoencoders: Toward a Meaningful and Decodable Representation
CVPR 2022.6
摘要
本文探讨了使用 DPM 进行表示学习的可能性,并通过自动编码器提取输入图像的有意义且可解码的表示。我们的关键思想是使用可学习的编码器来发现高级语义,并使用 DPM 作为解码器来对剩余的随机变化进行建模。我们的方法可以将任何图像编码成两部分的潜在代码,其中第一部分在语义上是有意义的和线性的,第二部分捕获随机细节,允许精确的重建。这种两级编码提高了去噪效率,并能够推进各种下游任务。
论文背景
本文提出了一种基于 diffusion 的自动编码器,它利用强大的 DPM 进行可解码表示学习。
找到可解码的有意义的表示需要捕获 高级语义 和 低级随机变化。特别是,我们使用去噪扩散隐式模型 (DDIM) 的条件变体作为解码器,并将潜在代码分成两个子代码。第一个“语义”子码是紧凑的,并使用 CNN 编码器推断,而第二个 “随机”子码 是通过反转我们以语义子码为条件的 DDIM 变体的生成过程来推断的。与其他 DPM 相比,DDIM 将前向过程修改为非马尔可夫过程,同时保留 DPM 的训练目标。这种修改允许将图像确定性地编码为其相应的初始噪声,这代表了我们的随机子代码。
提出方法
为了追求有意义的潜在代码,我们设计了一个以附加潜在变量
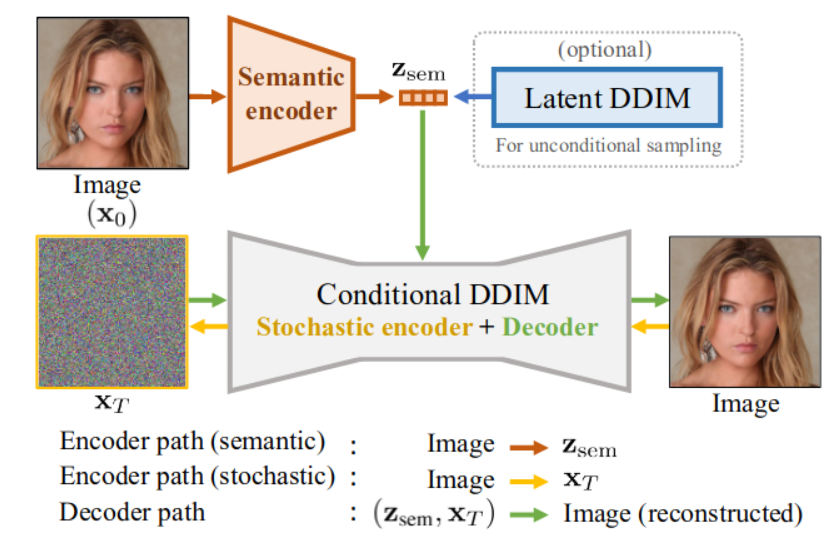
本文的
基于diffusion的解码器
我们的条件 DDIM 解码器 接收输入 z = (z_{sem}, x_T )
以生成输出图像。该解码器是一个条件 DDIM,对
用自适应组归一化层 (AdaGN) 调节 UNet。
它通过在归一化特征映射
自适应组归一化就是对输入h先进行归一化,再进行仿射变换。变换参数是从条件学出来的。
语义编码器
语义编码器
随机编码器
除了解码之外,我们的条件 DDIM
还可用于通过向后运行其确定性生成过程,将输入图像编码为随机特征
可以将此过程视为随机编码器,因为鼓励 xT 仅对 zsem 遗漏的信息进行编码,zsem 压缩随机细节的能力有限。
通过使用语义编码器和随机编码器,我们的自动编码器可以捕获输入图像的最后细节,同时还为下游任务提供高级表示
使用扩散自动编码器进行采样
解码器以
首先训练语义编码器 (φ) 和图像解码器 (θ),直到收敛。
然后,固定语义编码器,训练latent DDIM (ω)。在实践中,由潜在 DDIM
建模的潜在分布首先被归一化为零均值和单位方差。因此,来自扩散自动编码器的无条件采样是通过从潜在
DDIM 中采样
结论
扩散自编码器 可以输入图像中分别推断出 语义信息 和 随机信息。本工作的潜在表示能够提供精确的解码,同时包含对下游任务很有用的紧凑语义。