CMU15-445 PROJECT3 Query Executor 项目记录
项目背景
首先讨论查询处理的基本知识。在这个项目中,需要自己构建SQL查询,以测试执行器实现。
下面的图片是BusTub的架构概览:
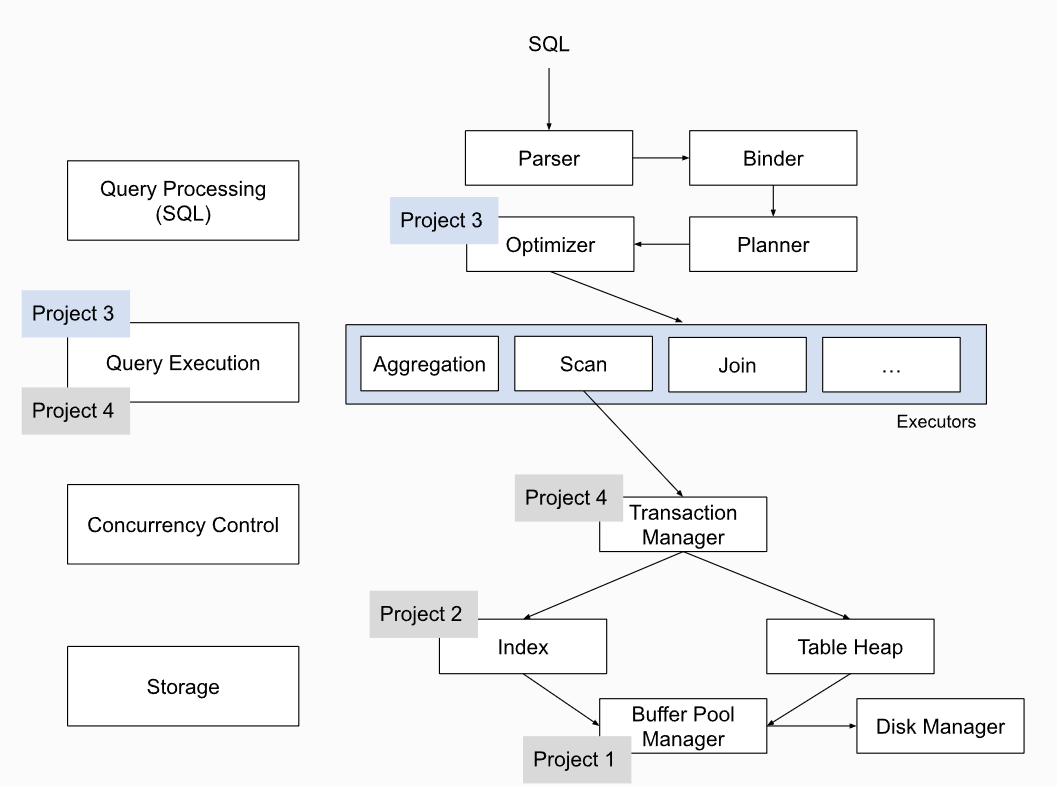
在前两个实验中,我们实现了缓存池Buffer Pool Manager以及B+树索引。都是为了为SQL语句执行提供支持。
缓存池Buffer Pool Manager:负责将请求的page放到内存供引擎访问。数据库中的缓存称为缓冲池,缓冲池存在的唯一目的就是提高数据库系统性能。 缓冲池本质上是分配给数据库管理器管理的一块内存空间,用于读写数据页。
通过将部分常用或者需要预取的数据存放在缓冲池以便系统直接访问和操作可以减少磁盘I/O,合理的缓冲池空间和好的缓冲池页面替换算法(提高命中率)可以大大提高数据库系统的性能。
B+树索引:属于Access Method。是一种用来对数据库数据进行读或写的方式。
SQL语句流程
应用程序连接到数据库系统并发送一个 SQL 查询,该查询可能被重写为不同的格式。SQL 字符串被解析(parse)成组成语法树的token。Binder 通过查询系统目录将语法树中的命名对象转换为内部标识符。Binder发出一个逻辑计划,该计划可以提供给tree rewriter以获得额外的模式信息。逻辑计划提供给优化器Optimizer,优化器选择最有效的过程来执行计划。
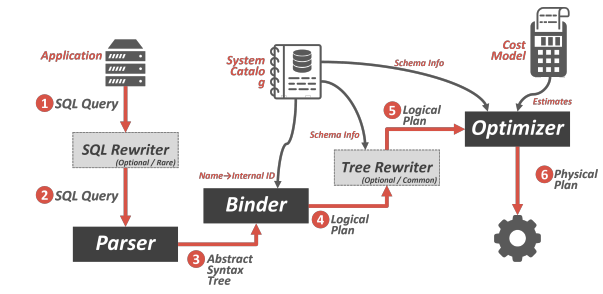
parser
一条 sql 语句,首先经过 Parser 生成一棵抽象语法树 AST。具体如何生成,参考编译原理。Parser 不是数据库的核心部分,也不是性能瓶颈,因此除非热爱编译原理,或者想通过实现一个 sql Parser 对编译原理进行实践,否则一般都会采用第三方库。Bustub 中采用了 libpg_query 库将 sql 语句 parse 为 AST。
Binder
在得到 AST 后,还需要将这些词语绑定到数据库实体上,这就是 Binder 的工作。Binder 遍历 AST,将这些词语绑定到相应的实体上。实体是 Bustub 可以理解的各种 c++ 类。绑定完成后,得到的结果是一棵 Bustub 可以直接理解的树。把它叫做 Bustub AST。
Planner
得到 Bustub AST 后,Planner 遍历这棵树,生成初步的查询计划。查询计划也是一棵树的形式。
数据库的Planner是数据库管理系统的一个组件,用于处理和优化SQL语句。它的主要作用是根据SQL查询语句和数据库结构,生成查询执行计划,以便快速地检索和处理数据。
Planner的工作流程如下:
- 首先,它接收到一个SQL查询语句。
- 接下来,Planner分析查询语句,确定查询的语义和查询中涉及的表、列等信息。
- 然后,Planner检查数据库的元数据信息,如表的大小、索引等,以确定最优的查询执行计划。
- 最后,Planner生成查询执行计划并返回给执行引擎执行。
Planner的优化可以大大提高查询性能和响应时间,特别是对于大型的数据库系统和复杂的查询语句。Planner使用了多种技术来优化查询执行计划,包括索引优化、查询重写、查询合并等。
Optimizer
Optimizer可以解释SQL查询语句并生成一个执行计划,该计划是指定最优执行方式的一个详细指令序列。
Optimizer主要的作用是对SQL查询进行优化,以提高查询性能和减少执行时间。它可以对SQL查询进行各种转换和优化,例如选择最佳的执行计划、使用索引以及选择最优的连接方式等。
Optimizer 主要有两种实现方式:
Rule-based. Optimizer 遍历初步查询计划,根据已经定义好的一系列规则,对 PlanNode 进行一系列的修改、聚合等操作。例如我们在 Task 3 中将要实现的,将 Limit + Sort 合并为 TopN。这种 Optimizer 不需要知道数据的具体内容,仅是根据预先定义好的规则修改 Plan Node。
Cost-based. 这种 Optimizer 首先需要读取数据,利用统计学模型来预测不同形式但结果等价的查询计划的 cost。最终选出 cost 最小的查询计划作为最终的查询计划。
Bustub 的 Optimizer 采用第一种实现方式。
另外值得一提的是,一般来说,Planner 生成的是 Logical Plan Node,代表抽象的 Plan。Optimizer 则生成 Physical Plan Node,代表具体执行的 Plan。在 Bustub 中,并不区分 Logical Plan Node 和 Physical Plan Node。Planner 会直接生成 Physical Plan Node。
Executor
Optimizer 生成的具体的查询计划后,就可以生成真正执行查询计划的一系列算子。每种查询计划都有与之对应的算子,也是实验三需要实现的部分。具体的过程是,遍历查询计划树,将树上的 Plan 替换成对应的 Executor。最终BusTub 通过火山模型(Iterator Model)执行算子并采用Bottom-to-Top,从叶子节点算子开始,向上层算子 push 自己的数据。
Iterator Model:每个算子都有 Init() 和 Next() 两个方法。Init() 对算子进行初始化工作。Next() 则是向下层算子请求下一条数据。当 Next() 返回 false 时,则代表下层算子已经没有剩余数据,迭代结束。可以看到,火山模型一次调用请求一条数据,占用内存较小,但函数调用开销大,特别是虚函数调用造成 cache miss 等问题。
另外补充一下Materialization Model 和 Vectorization Model。Materialization Model和 Iterator Model 相反,所有算子立即计算出所有结果并返回。这种模型的弊端显而易见,当数据量较大时,内存占用很高。但减少了函数调用的开销。
Vectorization Model 对上面两种模型的中和,一次调用返回一批数据。目前比较先进的 OLAP 数据库都采用这种模型。
Task #1 - Access Method Executors
Task 1 包含 4 个算子,SeqScan、Insert、Delete 和 IndexScan。
SeqScan
Catalog 实现
DBMS将数据库的元数据存储在内部的catalog中。Bustub 的 Catalog
提供了一系列 API,例如
CreateTable()、GetTable() 等等。Catalog
维护了几张 hashmap,保存了 table_id 和 table_name 到
table_info 的映射关系。table_id 由 Catalog
在新建 table 时自动分配,table name 则由用户指定。
- Schema
schema 就是数据库对象的集合,这个集合包含了各种对象如:表、视图、存储过程、索引等。schema 规定一张表是如何存储数据。
- TableInfo
TableInfo 维护的是一张表的所有元数据(Metadata),包括一张表的
schema_,表的名称name_,表的唯一标识
oid_,以及指向 table heap 的指针table_。
1 | |
TableHeap 是管理 table 数据的结构,包含
InsertTuple()、MarkDelete() 一系列 table
相关操作。TableHeap 本身并不直接存储 tuple 数据,tuple 数据都存放在
table page 中。table heap 可能由多个 table page 组成,仅保存其第一个
table page 的 page id。需要访问某个 table page 时,通过 page id 经由
buffer pool 访问。
tuple 对应数据表中的一行数据。每个 tuple 都由 RID 唯一标识。
- IndexInfo
类似的IndexInfo
维护的是一个索引表的所有元数据(Metadata),比如该索引 key
所在表的名称name_,索引名称index_、索引唯一表示
idoid_ 等信息。
Insert & Delete
Insert 和 Delete 这两个算子实现起来基本一样。
Insert 和 Delete 时,记得要更新与 table 相关的所有 index。index 与 table 类似,同样由 Catalog 管理。需要注意的是,由于可以对不同的字段建立 index,一个 table 可能对应多个 index,所有的 index 都需要更新。
1 | |
Insert 时,直接将 tuple 追加至 table 尾部。Delete 时,并不是直接删除,而是将 tuple 标记为删除状态,也就是逻辑删除。
IndexScan
使用 B+Tree Index Iterator 遍历 B+ 树叶子节点。由于我们实现的是非聚簇索引,在叶子节点只能获取到 RID,需要拿着 RID 去 table 查询对应的 tuple。
Task #2 - Aggregation & Join Executors
Task 2 包含 3 个算子,Aggregation、NestedLoopJoin 和 NestedIndexJoin。
Aggregation
AggregationExecutor 的成员如下: 1
2
3
4
5
6
7
8
9private:
/** The aggregation plan node */
const AggregationPlanNode *plan_;
/** The child executor that produces tuples over which the aggregation is computed */
std::unique_ptr<AbstractExecutor> child_;
/** Simple aggregation hash table */
SimpleAggregationHashTable aht_;
/** Simple aggregation hash table iterator */
SimpleAggregationHashTable::Iterator aht_iterator_;
Aggregation 算子会打破 iteration model 的规则。原因是,在 Aggregation 的 Init() 函数中,我们就要将所有结果全部计算出来。
SimpleAggregationHashTable 维护一张 hashmap,键为
AggregateKey,值为 AggregateValue。
key 代表 group by 的字段的数组,value 则是需要 aggregate 的字段的数组。
在下层算子传来一个 tuple 时,将 tuple 的 group by 字段和 aggregate
字段分别提取出来,调用 InsertCombine() 将 group by 和
aggregate 的映射关系存入 SimpleAggregationHashTable。
若当前 hashmap 中没有 group by 的记录,则创建初值;若已有记录,则按 aggregate 规则逐一更新所有的 aggregate 字段。
在 Init() 中计算出整张 hashmap 后,在 Next() 中直接利用 hashmap iterator 将结果依次取出。Aggregation 输出的 schema 形式为 group-bys + aggregates。
NestedLoopJoin
DBMS将默认使用 NestedLoopJoinPlanNode 进行所有的
join 操作。
伪代码大致如下: 1
2
3
4for outer_tuple in outer_table:
for inner_tuple in inner_table:
if inner_tuple matched outer_tuple:
emitAbstractExpression
就是表达式树的节点。sql 中的所有表达式都会被 parse 为表达式树,在 Binder
中进行绑定。在 NestedLoopJoin 里,我们要用到的是
EvaluateJoin(),输入的是左右两个 tuple 和
schema。返回值是表示 true 或 false 的 value。true 则代表成功匹配。
NestedIndexJoin
在进行 equi-join 时,如果发现 JOIN ON 右边的字段上建了 index,则 Optimizer 会将 NestedLoopJoin 优化为 NestedIndexJoin。具体实现和 NestedLoopJoin 差不多,只是在尝试匹配右表 tuple 时,会拿 join key 去 B+Tree Index 里进行查询。如果查询到结果,就拿着查到的 RID 去右表获取 tuple 然后装配成结果输出。
Task #3 - Sort + Limit Executors and Top-N Optimization
Task 3 包含 3 个算子,Sort,Limit 和 TopN,将 Limit + Sort 在 Optimizer 中优化为 TopN。
Sort
在 Init() 中读取所有下层算子的 tuple,并按 ORDER BY 的字段升序或降序排序。
std::sort()
的第三个参数可以传入自定义的比较函数。直接传入一个 lambda
匿名函数。由于要访问成员 plan_ 来获取排序的字段,lambda 需要捕获 this
指针。另外,排序字段可以有多个,按先后顺序比较。第一个不相等,直接得到结果;相等,则比较第二个。不会出现所有字段全部相等的情况。
1 | |
Limit
实现起来比较简单。在内部维护一个 count,记录已经 emit 了多少 tuple。当下层算子空了或 count 达到规定上限后,不再返回新的 tuple。
TopN
仅需返回最大/最小的 n 个 tuple。用 std::priority_queue
加自定义比较函数,然后在 Init() 中遍历下层算子所有
tuple,全部塞进优先队列后截取前 n 个。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15std::priority_queue<Tuple, std::vector<Tuple>, decltype(cmp)> pq(cmp);
Tuple child_tuple{};
RID child_rid;
while (child_->Next(&child_tuple, &child_rid)) {
pq.push(child_tuple);
if (pq.size() > plan_->GetN()) {
pq.pop();
}
}
while (!pq.empty()) {
child_tuples_.push(pq.top());
pq.pop();
}
Sort Limit As TopN
在 Optimizer 里增加一条规则,将 Sort + Limit 优化为 TopN。
首先要了解一下 Optimizer 是如何进行优化的。 1
2
3
4
5
6
7
8
9
10
11
12
13
14auto Optimizer::Optimize(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
if (force_starter_rule_) {
// Use starter rules when `force_starter_rule_` is set to true.
auto p = plan;
p = OptimizeMergeProjection(p);
p = OptimizeMergeFilterNLJ(p);
p = OptimizeNLJAsIndexJoin(p);
p = OptimizeOrderByAsIndexScan(p);
p = OptimizeSortLimitAsTopN(p);
return p;
}
// By default, use user-defined rules.
return OptimizeCustom(plan);
}
让未经优化的原始 plan 树依次经历多条规则,来生成优化过的 plan。task3就是让我们新增一条规则。
出现 上层节点为 Limit,下层节点为 Sort 的形式时,则可以优化为一个 TopN 算子。同样,我们对 plan tree 进行后续遍历,在遇到 Limit 时,判断其下层节点是否为 Sort,若为 Sort,则将这两个节点替换为一个 TopN。
1 | |
Leaderboard Task (Optional)
Query 1: Where's the Index?
1 | |
使用HashJoin来处理equi-condition;连接重排序来挑选t1的索引;根据cardinality(使用EstimatedCardinality函数),先连接t2和t3。
主要优化方向是把 NestedLoopJoin 替换为 HashJoin、Join Reorder
让小表驱动大表,以及正确识别 t1.x 上的索引。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38auto *outer_expr = dynamic_cast<const ComparisonExpression *>(&nlj_plan.Predicate());
auto left_outer_expr = dynamic_cast<const ColumnValueExpression *>(outer_expr->children_[0].get());
auto right_outer_expr = dynamic_cast<const ColumnValueExpression *>(outer_expr->children_[1].get());
auto inner_pred = std::make_shared<ComparisonExpression>(
std::make_shared<ColumnValueExpression>(
0, left_outer_expr->GetColIdx() - left_nlj_plan.GetLeftPlan()->output_schema_->GetColumnCount(),
left_outer_expr->GetReturnType()),
std::make_shared<ColumnValueExpression>(1, right_outer_expr->GetColIdx(),
right_outer_expr->GetReturnType()), ComparisonType::Equal);
auto outer_pred = std::make_shared<ComparisonExpression>(
std::make_shared<ColumnValueExpression>(0, right_expr->GetColIdx(), right_expr->GetReturnType()),
std::make_shared<ColumnValueExpression>(1, left_expr->GetColIdx(), left_expr->GetReturnType()),
ComparisonType::Equal);
auto right_column_1 = left_nlj_plan.GetRightPlan()->output_schema_->GetColumns();
auto right_column_2 = nlj_plan.GetRightPlan()->output_schema_->GetColumns();
std::vector<Column> columns;
columns.reserve(right_column_1.size() + right_column_2.size());
for (const auto &col : right_column_1) {
columns.push_back(col);
}
for (const auto &col : right_column_2) {
columns.push_back(col);
}
std::vector<Column> outer_columns(columns);
for (const auto &col : left_nlj_plan.GetLeftPlan()->output_schema_->GetColumns()) {
outer_columns.push_back(col);
}
return std::make_shared<NestedLoopJoinPlanNode>(
std::make_shared<Schema>(outer_columns),
std::make_shared<NestedLoopJoinPlanNode>(std::make_shared<Schema>(columns),
left_nlj_plan.GetRightPlan(), nlj_plan.GetRightPlan(),
inner_pred, JoinType::INNER),
left_nlj_plan.GetLeftPlan(), outer_pred, JoinType::INNER);
Query 2: Too Many Joins!
1 | |
按照原执行计划,所有的 JOIN 全部写成了 FULL JOIN,然后所有 Filter 在 plan tree 的顶端。
优化的方法就是把 Filter 正确下推至 Join 算子下。需要注意的时,我们下推的不是整个 Filter 节点,实际上是节点中的 predicate。我的做法是遍历表达式树,提取 predicate 中的所有 comparison,判断表达式的两边是否一个是 column value,一个是 const value,只有这样的 predicate 可以被下推,再将所有的 predicate 重新组合为 logic expression,生成新的 Filter,根据 column value 的 idx 来选择下推的分支。
Query 3: The Mad Data Scientist
1 | |
遇到 Projection + Aggregation,改写 aggregates,截取 Projection 中需要的项目,其余直接抛弃。具体实现是收集 Projection 里的所有 column,然后改写下层节点,仅保留上层需要 project 的 column。
1 | |