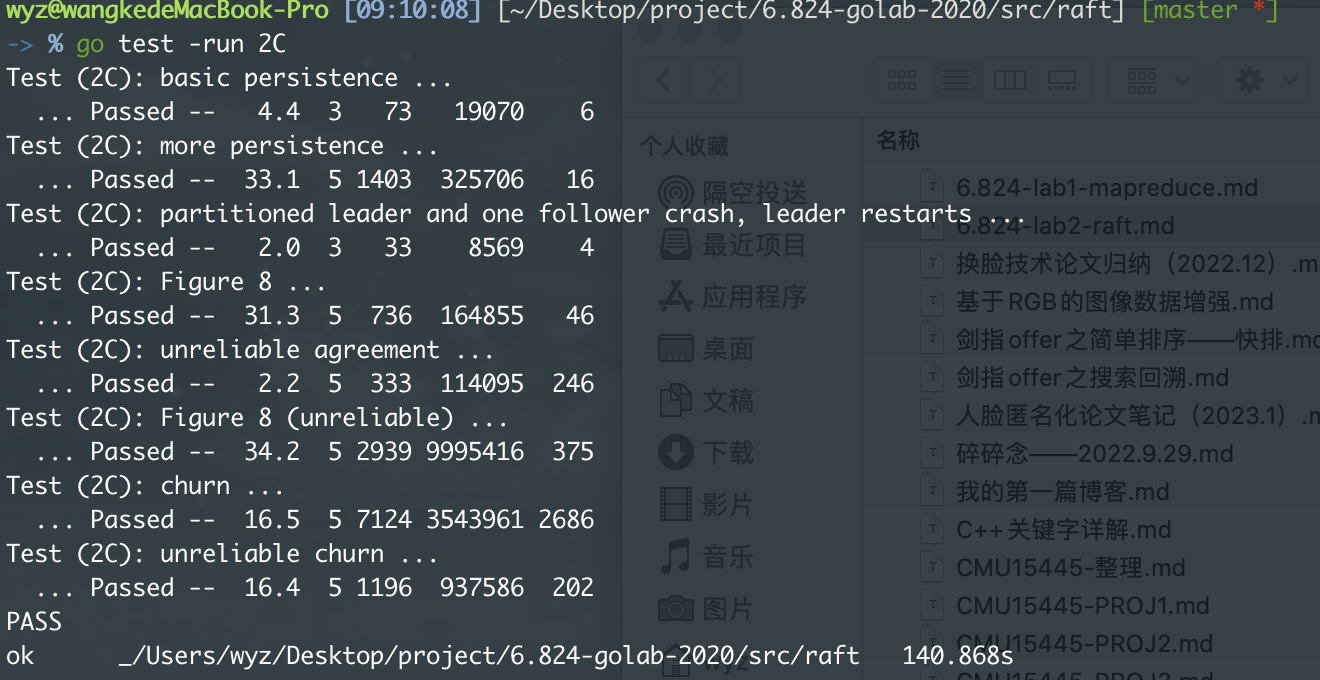
MIT6.824 lab2 raft 项目记录
6.824lab2要求实现raft算法,将 Raft 实现为 Go 对象类型。
Raft通过选举leader、日志复制和安全性三个子问题来解决共识问题。leader负责管理日志,接受客户端的日志条目,并将其复制到其他服务器。Raft通过随机化方法简化了leader选举算法。Raft服务器之间通过RPC进行通信,基本共识算法只需要两种类型的RPC。Raft的日志复制机制保证了线性化语义,即每个操作都立即执行,且只执行一次。Raft还提供了一种机制来保证领导者选举的完整性,即 leader 必须拥有所有已提交的日志条目。Raft解决了与重新配置相关的问题,包括新服务器可能没有存储任何日志条目、集群leader可能不是新配置的一部分 以及 被移除的服务器可能会破坏集群。
Part 2A - Leader Election
实现 Raft leader election 和 heartbeats(没有 log entries 的 AppendEntries RPC)。 2A 的目标是选出单个leader,如果没有故障,leader将继续担任;如果 老leader 发生故障 或 发往/来自 老leader的数据包丢失,则新的leader将接管。
具体过程可以参见 领导者选举
选举发起逻辑
在 Make()中创建后台 goroutine,
当有一段时间没有收到其他节点的消息时,它将通过发送RequestVote
RPC来定期启动 leader 选举。
1 | |
当electionTimer完成计时,即在ElectionTimeout时间内没有收到消息时,节点就会发起选举。需要注意的是这里
electionTimer
的计时不等于固定的ElectionTimeout,而是使用随机时间间隔。
1 | |
其作用是减少同时选举的可能性,分散网络负载,提高选举成功率。避免选举活锁(Election Livestock),即避免节点反复进入选举状态但又无法选出leader。
发起选举后,该节点的状态变为candidate , 并对每个 peer
启动 goroutine 发送 RequestVote RPC 请求。直到出现 3 种情况时,节点退出
candidate状态:
- 赢得选举,成为
leader - 另一个节点抢先成为
leader - 一段时间过去后仍然没有
leader
当candidate赢得选举,它会成为leader并向所有其他节点发送心跳来确认其权威。
RequestVote RPC 实现
RequestVote RPC是Raft算法中用于选举leader
的RPC请求,其作用是请求其他服务器投票给自己。
请求参数RequestVoteArgs:
Term:当前candidate节点的任期CandidateId:当前candidate节点的编号LastLogIndex:当前candidate节点最后一个日志的索引LastLogTerm:当前candidate节点最后一个日志的term值
返回值RequestVoteReply:
Term:接受投票节点的term值, 主要用来更新当前candidate节点的term值VoteGranted:是否给该申请节点投票
初始化
reply.Term = rf.term reply.VoteGranted = false
一个节点(无论当前是什么状态)在接收到RequestVote RPC消息时, 会从上往下按以下条件依次判断:
- 如果
args.Term < rf.term, 则立刻返回; - 如果
args.Term == rf.term:- 如果投票节点已经是
leader就直接返回; - 如果投票节点的
votedFor不为-1并且不等于candidateId则立刻返回; - 如果
voteFor等于candidateId则同意投票,置reply.VoteGranted为true
- 如果投票节点已经是
- 如果
args.Term > rf.term:首先置投票节点rf.term = args.Term,voteFor置-1并且转换为Follower状态。进入下一步判断:- 如果
lastLogTerm > args.LastLogTerm || (lastLogTerm == args.LastLogTerm && args.LastLogIndex < lastLogIndex两种情况下直接返回(注意返回的 term 是更新后的args.Term)。 - 其他情况下,令
voteFor = args.CandidateId并将reply.VoteGranted置为 true,将状态切换为Follower就返回。
- 如果
Append Entries RPC的简单实现
AppendEntries RPC是Raft算法中用于复制日志条目的RPC请求,其作用是将领导者的日志条目复制到其他服务器上。
leader 定期发送 AppendEntries 消息(心跳包)给每个节点, 以此来维持自己的leader地位。
1 | |
Make()中服务器需要为每个raft节点创建一个appendEntriesTimer,使用长度为len(peers)的切片实现,定时时长为HeartBeatTimeout
。并且为除了自身外的所有节点创建goroutine,定期向节点发送Append Entries RPC。
Append Entries
RPC:在2A中主要实现resetElectionTimer功能,确定leader的权威,防止其他节点发起选举。在
rf.term > args.Term
的情况下忽略该心跳,否则将自身term改为args.Term,将自身状态改为follower,并且重置选举计时器。
在测试中会出现一个问题:在网络不出错的情况下sleep一段时间,任期会发生变化,说明发生了不必要的选举。
1 | |
所以在具体实现中我在 rf.term > args.Term
的情况下也进行了resetElectionTimer()。重置选举计时器可能是为了保持系统的稳定,直到新的领导者被选举出来。在这段时间里,避免不必要的选举可能是有益的,尤其是在网络条件不稳定或者有多个领导者竞争的情况下。
一些小技巧 Tricks
Log For Debugging
在raft中加入DebugLog布尔变量,表示是否打印log。
1 | |
在打印日志的时候,就可以调用 rf.log()
自由地填写一些备注信息,方便定位问题。

Part 2B - Append Entries
在Raft协议中,AppendEntries是一种核心的RPC,需要实现一下几个功能:
- 日志复制
AppendEntriesRPC用于将领导者的日志条目复制到跟随者。领导者将新的logEntry添加到其自身的日志中,然后通过AppendEntriesRPC将这些LogEntries发送给所有跟随者。当跟随者接收到AppendEntriesRPC时,它们将领导者的日志条目添加到自己的日志中。 - 领导者维持
即使没有新的日志条目,领导者也会定期发送
AppendEntriesRPC作为心跳信号,以维持其领导者地位。这在上一个part中已经实现。 - 提交日志条目
当领导者的日志条目被复制到集群中的大多数节点(
if count > len(rf.peers)/2)时,领导者可以将这些条目标记为commited。AppendEntriesRPC包含一个LeaderCommit字段,该字段告诉跟随者领导者已经提交了哪些日志条目。 - 日志一致性检查
AppendEntriesRPC包含prevLogIndex和prevLogTerm字段,用于帮助检查领导者和跟随者的日志是否一致。如果跟随者的日志在prevLogIndex处的条目的term与prevLogTerm不匹配,跟随者将拒绝AppendEntriesRPC。
具体过程可以参见 日志复制
Append Entries RPC的完整实现
请求参数AppendEntriesArgs:
Termleader当前任期LeaderIdleader的id,使得跟随者可以重定向客户端PrevLogIndex新日志之前的日志条目索引PrevLogTerm索引为PrevLogIndex日志条目的任期Entries需要同步的日志条目(如果只是发送心跳就置为空,可以一次性发送多个条目)LeaderCommit领导者的commitIndex
返回值 AppendEntriesReply :
Term服务器的任期Success如果follower包含与prevLogIndex匹配的条目,并且这个条目的term与prevLogTerm相同,则结果为true。
按照论文中的步骤来实现:
- 如果 args.term < rf.term,就返回false;
- 如果 日志不存在logterm == PrevLogTerm 的 PrevLogIndex 对应的条目,就返回false;翻译成程序语言
1 | |
如果现有条目与新条目(index相同但term不同)冲突,则删除现有条目及其后面的所有条目。在这里我没有做删除操作,而是找到上个 term 的最后一条 log 的 index,用reply的一个返回值返回给leader。程序语言:
1
2
3
4for idx > rf.commitIndex && idx > rf.lastSnapshotIndex && rf.logEntries[rf.getIndexByLogIndex(idx)].Term == term {
idx -= 1
}
reply.NextIndex = idx + 1如果 leaderCommit > commitIndex, 设置 commitIndex =min(leaderCommit, index of last new entry)。
- 当 follower 收到
AppendEntriesRPC 时,如果leaderCommit大于 follower 的commitIndex,则表明 leader 有更多的日志条目已经被提交了。 - 然而,follower 不应该盲目地将其
commitIndex更新为leaderCommit,因为它可能还没有收到所有的日志条目。如果直接设置commitIndex = leaderCommit,而 follower 的日志中还没有leaderCommit索引处的条目,这将导致问题。
而我们现在考虑一个场景:假设我们有三台服务器,并且 S0 被选为领导者。S0 从客户端接收一些命令并将它们添加到其日志中(例如,1:100、1:101 和 1:102,格式为 term:command)。然后,在将这些条目发送到任何客户端之前,S0 立即与其余服务器失去联系。接下来,S1 被选举为领导者。它获取两个命令 2:103 和 2:104,并将它们复制到 S2(因此也提交它们)。紧接着,S1 被断开,S0 被重新连接。S2 现在将被选举为领导者,因为 S0 上的日志不是最新的。S0 将从
AppendEntries的RPC请求助中得知 S2 的LeaderCommit为 2 ,但它不应该从其日志中提交任何命令,因为其日志与 S2 的日志不匹配。如果没有来自客户端的新命令,我们什么时候应该删除 S0 上所有冲突的日志条目?
这种情况下,根据第三步,S0会找到“上个 term 的最后一条 log 的 index”,因为S0记录的term是1,所以S0会找到index 0,然后返回NextIndex为1。
再记录一个自己思考了一会儿的一个问题:感觉通常情况下 nextIndex 和 matchIndex是相差1的关系,matchIndex <= nextIndex - 1,等于的情况我能理解,什么时候会出现小于呢?
- 如果出现日志不一致的情况,例如,follower 的日志落后于 leader
的日志,那么
nextIndex会被递减以尝试找到一个匹配点。 - 初始化:其实主要是初始化的问题。在刚开始或者 leader
切换的时候,也可能出现
matchIndex小于nextIndex - 1的情况,因为nextIndex会被 初始化 为 leader 日志的最后一个条目的索引加一,而matchIndex会被初始化为 0 。 nextIndex是对领导者与给定follower共享的前缀的 猜测。它通常是相当乐观的,只有在收到失败 reply 时才会倒退。例如,当一个leader刚刚被选举出来时,nextIndex被设置为日志末尾的index索引。在某种程度上,nextIndex用于最大化性能——你只需要将这些东西发送给该server。matchIndex用于安全。它是领导者与给定追随者共享的日志前缀的 保守度量。matchIndex永远不能设置为太高的值,因为这可能会导致commitIndex向前移动太远。这就是为什么matchIndex初始化为0(即我们同意没有前缀),并且仅在追随者积极确认RPC 时才更新AppendEntries。
Update CommitIndex 以及 apply
在commitIndex发生改变的时候,需要进行一次apply的尝试。
对leader而言,每次收到 true 的 AppendEntries RPC
reply时,如果确定多数节点对于该index已经match的,就发送一个rf.notifyApplyCh <- struct{}{};
对follower而言,在上述Append Entries
RPC实现的第四步中,commitIndex可能会发生改变,此时也要发送rf.notifyApplyCh <- struct{}{}。
节点的notifyApplyCh收到信号时,则开始startApplyLogs。将需要apply的msgs逐个同步到applyCh(这个chan由客户端提供)。
1 | |
Leader Append Entries to Peer 逻辑
在2A中我们已经实现了leader向其他节点发送心跳的逻辑,对每个节点创建goroutine发送AppendEntries RPC。
在2B中我们需要对RPC的返回值reply作处理。
首先,有最基本的对于所有server都需要的,当收到的reply的Term比自身的term大时,立马乖乖的变成follower,并把自身 term 置为该 term。
然后如果AppendEntries成功了,则更新nextIndex以及matchIndex,并在此时进行论文Figure2中更新commitIndex的操作。如果leader确定该index的条目已经同步到大多数节点,就更新commitIndex为该index。
If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N
另外,只要reply.NextIndex不为0,就要把对应的nextIndex更新。这里有个bug找了老半天,就是缺了这一步,会出现config.go:475: one(106) failed to reach agreement。当一个服务器断联又加回来之后,有可能出现未达成共识的问题。原因就是在这时需要更新对应的nextIndex。
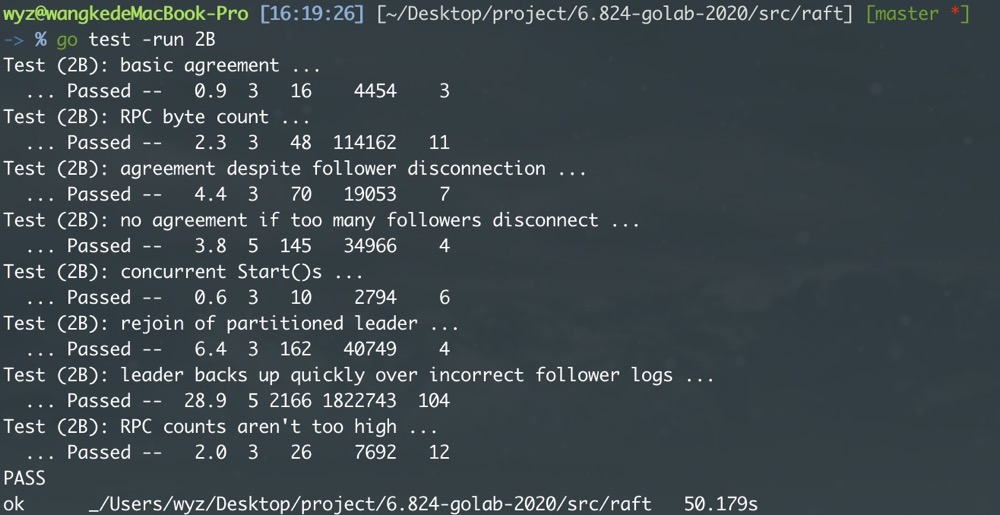
Part 2C - Persistence
这部分的代码比较简单,按照课程给的示例代码实现即可。
1 | |
然后在这些变量发生改变的时候rf.peisist()即可。
在这里我是很顺利的就过了。但据说这里有个难过的点
Figure 8 (unreliable).
原因是 前期因为网络被设置为 unreliable 并且经常搞点 connect
disconnect 的小动作,导致会有一大堆 Log
冲突(几百条),后期挨个retry找nextIndex很容易导致超时。而我在实现的过程中就已经参考论文在AppendEntries的第3步中实现,即找到上个
term 的最后一条 log 的
index,用reply的一个返回值NextIndex返回给leader.