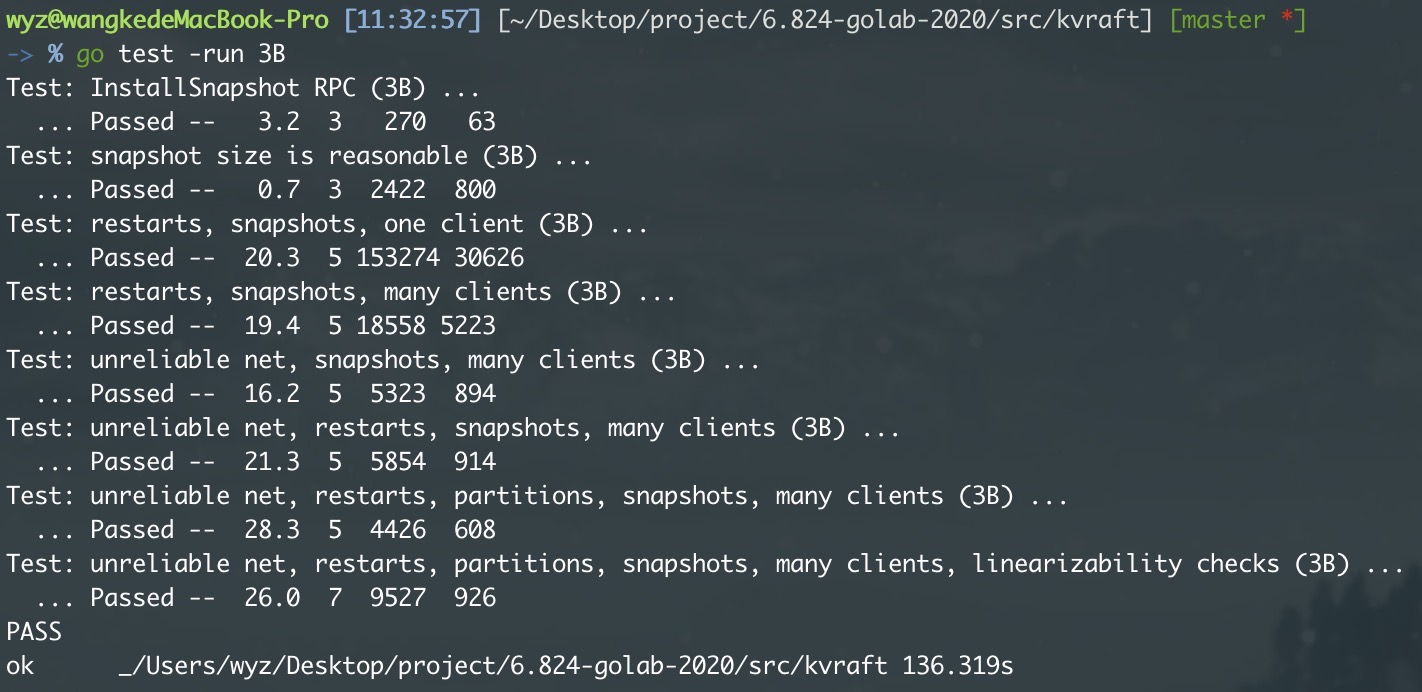
MIT6.824 lab3 容错kv服务 项目记录
本实验使用 lab2 中的 Raft 库构建容错kv存储服务 。
kv服务是一个复制状态机,由多个使用 Raft 进行复制的kv服务器组成。只要大多数服务器处于活动状态并且可以通信,无论存在其他故障或网络分区,该服务都应该继续处理客户端请求。
我们需要基于 Raft 实现一个容灾备份的 Key-Value 存储,并保证其强一致性。
所谓 强一致性,一般指 线性一致性(Linearizable Consistency),其条件如下:
- 任何一次读都能读取到某个数据最近的一次写的数据。
- 所有进程看到的操作顺序都跟全局时钟下的顺序一致。
1 | |
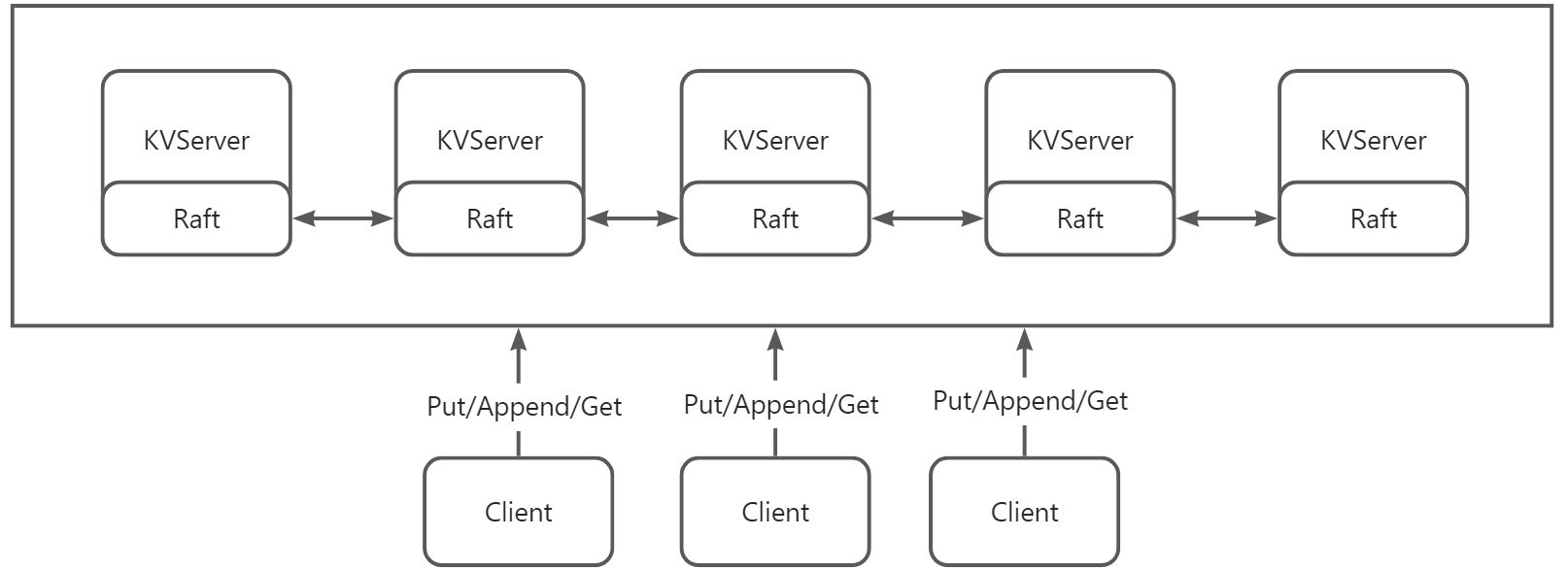
Part 3A :无日志压缩的k/v服务
基本实现
基本的实现步骤:
- client 通过一个
clerk结构来向 server 发送Get/Put/Append等 RPC 请求。 - server 收到后,如果其背后的 raft 不是 Leader,返回
ErrWrongLeader,让 client 寻找真正的 Leader。 - 如果 server 背后的 raft 是 Leader,用 raft 的
Start()开始对这次的请求进行共识,放进 logEntries。 - 在放进 logEntries 后,raft 通过 applyCh 将消息传达过来,server 将这个操作真正执行到状态机中,并返回 client 发来的 RPC 的 reply。
分析
当我们收到请求时,我们应该先通过 Start
接口将请求的操作同步到各个节点,然后各个节点再根据请求具体的操作
(Put/Append/Get)来执行对应的逻辑,这样就可以保证各个节点的线性一致性。
怎么处理重复请求,或者说怎么实现幂等性?
如果客户端没有收到响应,它可能会重试请求。Raft 应当确保即使这些请求被重复执行,也不会影响系统的最终状态。
日志复制(Log Replication):每个请求在 Raft 中都会作为一个日志条目被追加。这些日志条目包含了需要执行的命令以及一个唯一的序列号。序列号保证了每个命令的唯一性,即使有重复的请求,也可以通过检查序列号来识别并忽略重复的命令。
server端使用
lastApplies数组来存储各个client(以clientId标记)的上一次apply的msgId,借此来判断是否重复。1
2
3
4
5
6func (kv *KVServer) isRepeated(clientId int64, id msgId) bool {
if val, ok := kv.lastApplies[clientId]; ok {
return val == id
}
return false
}日志一致性(Log Consistency):领导者在接收到客户端的请求后,会首先将请求作为新的日志条目添加到其日志中。然后,它会将该日志条目复制到集群中的其他服务器上。只有当大多数的服务器都已经复制了这个日志条目,该命令才会被执行。这个过程确保了即使有重复请求,也只有一个请求会被执行。
领导者选举(Leader Election):在发生领导者更换的情况下,新的领导者会继承前任领导者的日志,并在其基础上进行操作。这样可以保证即使在领导者更换期间出现重复请求,也不会导致状态不一致。
超时处理及重试机制
实际情况更加复杂,server可能会出现超时情况。领导者server崩了或者raft共识失败等等情况,需要有适当的重试机制处理。
client端:
1 | |
超时则continue重试;不是leader则找下一个server。而且如果请求失败,client就等待一个ChangeLeaderInterval
的时长,避免多次重发请求增加server端负担。
server端:
1 | |
- 如果当前节点不是 leader,则设置响应错误为
ErrWrongLeader并返回。 - 创建一个新的通道
ch来接收通知消息。将此通道与操作请求 ID 关联并存储在kv.msgNotify中。 - 设置一个定时器
t,以WaitCmdTimeOut为超时时长。使用select语句等待两种情况之一:- 从通道
ch接收到响应,此时从kv.msgNotify中删除对应的条目,并返回接收到的响应。 - 超时事件发生,同样从
kv.msgNotify中删除条目,并设置响应错误为ErrTimeOut后返回。
- 从通道
线性一致性
raft的线性一致性主要得益于其日志复制(Log Replication)机制。
日志顺序:leader 按顺序将日志条目复制到其他节点。只有当大多数节点都复制了某个日志条目,该日志条目才会被commit。当一个操作被 raft commit 了,这就能够保证,它前面的所有操作都将在这次操作之前执行完毕。
一致性检查:当领导者与跟随者进行日志复制时,会包括前一个日志条目的信息作为一致性检查。如果不匹配,跟随者会拒绝新的日志条目。
另外,让我们考虑一个情况。
一个 get(1号 get) 还没返回,另一个 get(2号 get) 又发出来了,可能出于种种原因,1号 get 要重试,而 2 号 get 不用,导致 1 号 get 可能拿到比 2 号 get 更新的值,而且它的 log 甚至可能在 2 号之前。
这仍然算是线性一致的。当某些请求已经返回给客户端了,他们的结果已经被观测到了,那在他们返回之后发出的请求,一定要也能够观测到前面这些请求的影响。
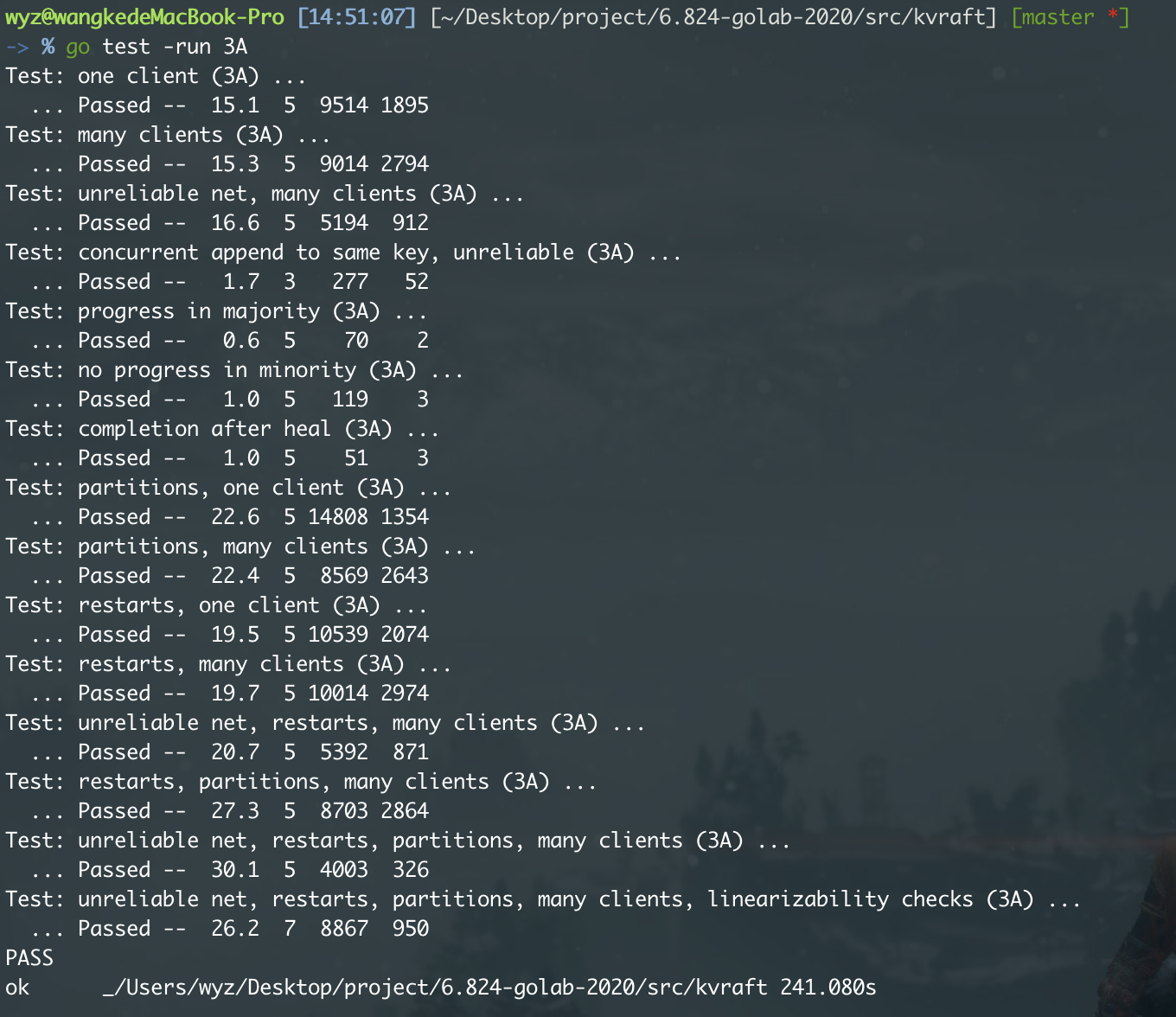
Part 3B :有日志压缩的k/v服务
对于一个长期运行的服务器来说,永远记住 Raft
的完整日志是不切实际的,全都是日志恢复起来也不方便。所以这里我们需要实现raft的snapshot来做checkpoint,在日志达到一定程度时,保存当前状态机的快照并把前面的日志删除。
kvserver 有时会持久存储其当前状态的snapshot ,而 Raft
将丢弃快照之前的日志条目。当服务器重新启动(或远远落后于领导者并且必须赶上)时,服务器先安装快照,然后重播创建快照之后的日志条目。
基本实现
- 触发快照
日志大小达到预设的阈值时触发快照。每个 server 根据 raft log 的size 独立判断 snapshot 的时机。
每次 apply 一条后,便可以检查一下 raft 的
size,即persister.RaftStateSize(),如果超过了maxraftstate
就 snapshot。
- 创建快照
捕捉状态:记录当前的系统状态,包括应用状态和Raft元数据(如当前的索引和任期)。
存储快照:将捕捉的状态存储在持久化存储中,通常是磁盘。
- 压缩日志
- 删除已经被快照包含的日志条目。
- 快照中包含的最后一个日志条目的 index 和 term 将用于后续的日志复制和日志一致性检查。
- 恢复快照
- 启动时恢复:如果节点重启,首先从最近的快照恢复状态。
- Leader election:如果新的领导者有更新的快照,其它节点可能需要从该快照恢复。
- InstallSnapshot:如果某个跟随者落后太多,领导者可以发送快照而不是全部缺失的日志。
分析
快照中有哪些内容?
kvserver层:Encode
kvserver层的data和lastApplies。其中lastApplies
记录各个 client 已经执行掉的 request。以
snapshotData []byte的形式传递给 raft层。
raft层:更新logEntries、lastSnapshotIndex以及lastSnapshotTerm。并通过在
Part2 中实现的getPersistData() 得到
persistData。再将这些data发送给peisister持久化。
1 | |
这里可以明晰 快照 和 持久化 的关系:
- 快照包括了系统状态以及到达该状态所必需的所有信息,例如在 Raft 中,快照包含了某个时刻的数据状态和必要的元数据。
快照的主要目的是用来 减少需要存储和复制的日志数量,从而节省存储空间,加快状态恢复和数据同步的速度。
- 持久化是指将数据保存到持久存储介质(如硬盘)的过程。持久化的主要目的是确保数据的耐久性和一致性。
快照是持久化的一种形式。快照保存了某一时刻的整个系统状态,而持久化则确保这些状态即使在系统故障后也能被保留和恢复。在系统恢复时,可以先从快照恢复到特定时刻的状态,然后使用之后的持久化日志条目来更新状态,直到达到最新状态。
Install Snapshot
安装快照的时机
- 跟随者落后太多
当一个 Follower 因为宕机或网络问题等原因长时间离线,并错过了大量的日志条目时,它在重连时可能会发现自己落后于当前的Leader很多。在这种情况下,leader 将发送快照而不是所有缺失的日志条目,因为发送大量日志条目可能非常低效。
- 日志已被压缩
当领导者已经对日志进行了压缩,并创建了快照来替代旧的日志条目时,如果 follower 请求的日志条目已经不在领导者的日志中了,leader会发送快照给follower。
1 | |
当 follower AppendEntries
返回失败(false)时,会同时带上NextIndex 供leader更新。
- 如果
reply.NextIndex > rf.lastSnapshotIndex,则表示 follower 要求的日志还在leader的log下; - 否则,leader就直接单独启动一个doroutine,给该节点发送快照。
如何安装快照
InstallSnapshot RPC的Args和Reply格式如下:
1 | |
Leader角色
- 检测需要发送快照:领导者会检测到跟随者需要的日志条目不再可用(因为已经被快照替代)。
- 发送快照:领导者向跟随者发送包含当前状态机快照的消息。这个快照包含了所有被压缩日志条目的信息。
需要注意的是,leader在发送InstallSnapshot RPC之后,还需要根据返回的Term判断自己的身份,并且更新该节点的matchIndex和nextIndex.
1 | |
Follower角色
- 接收快照:follower接收到快照数据后,需要将其本地状态机更新到快照所代表的状态。
- 更新本地状态:follower需要更新它的本地日志到快照的状态,这包括更新它的当前日志索引和任期。
- 持久化快照:follower将快照数据持久化存储,以确保在重启后能够从快照恢复状态。
Follower如果返回成功,在本机安装快照,就需要裁剪日志并作持久化,如下所示:
1 | |
启动恢复
kvserver启动时,需要在StartKVServer中进行恢复。
kv.readPersist(kv.persister.ReadSnapshot())