MIT6.824 lab4 sharded kv服务 项目记录
这个实验的任务是构建一个分片的键/值存储系统。在这个系统中,键值对被分配到一组 replaca 中的不同子集,这些子集称为“分片”。通过分片,每个raft组只处理一小部分分片的 put 和 get 操作,这样可以提高系统的整体吞吐量(单位时间内的 put 和 get 操作次数)。这个存储系统由两个主要部分组成:
- raft 副本组(replica group) :每个 raft 副本组负责一部分分片。一个 raft 副本组包含多个服务器,这些服务器使用 Raft 协议来复制该组的分片数据。
- 分片主控(Shard Master):分片主控决定哪个副本组负责哪个分片,用配置(configs)描述。configs 随时间变化,客户端需要咨询分片主控来找到负责特定键的副本组,副本组也要咨询分片主控以确定它们需要服务的分片。整个系统中只有一个分片主控,它作为一个容错服务,也使用 Raft 实现。
此外,存储系统还必须能够在raft副本组之间转移分片。原因是 一些副本组可能比其他组负载更重,需要移动分片以平衡负载,以及副本组可能加入或离开系统,例如,添加新的raft组以增加容量,或者将现有raft组下线进行修理或退役。
Part 4A: The Shard Master
Shard Master 是基于 raft 的 service,与 lab3
的处理方式一样。由于Configs一般比较小,甚至都不用实现 raft
的 snapshot.
Shard Master
需要提供高可用的集群配置管理服务,记录了每个组(Group)ShardKVServer的集群信息和每个分片(shard)服务于哪组(Group)ShardKVServer。具体实现通过Raft维护
一个Configs数组,具体内容如下:
Num:config numberShards:shard -> gid,分片位置信息,Shards[3]=2,说明分片序号为3的分片负责的集群是Group2(gid=2)Groups:gid -> servers[],集群成员信息,Group[3]=[“server1”,“server2”],说明gid = 3的集群Group3包含两台名称为server1 & server2的机器
Shard Master 需要实现 Join, Leave, Move, Query
四个服务。
Query: 查询最新的Config信息。Move将数据库子集Shard分配给GID的Group。Join: 新加入的Group信息,要求在每一个group平衡分布shard,即任意两个group之间的shard数目相差不能为1,具体实现每一次找出含有shard数目最多的和最少的,最多的给最少的一个,循环直到满足条件为止。GID = 0是无效配置,一开始所有分片分配给GID=0,需要优先分配;另外,map的迭代是无序的,不确定顺序的话,同一个命令在不同节点上计算出来的新配置不一致,按sort排序之后遍历即可。且map是引用对象,需要用深拷贝做复制。Leave: 移除Group,同样需要实现均衡,将移除的Group的shard每一次分配给数目最小的Group就行,如果全部删除,需要将shard置为无效的0。
分片均匀分布策略
shard Master 的核心功能是选择一个策略,让各个分片均匀地分布在
group 分片集群之中,平衡他们的压力。
我的策略大致思路如下:
现对较为特殊的简单情况做处理,再根据Groups数量与Shards数量的关系分别处理。
无
group- 如果
config.Groups长度为 0,表示没有group,那么将config.Shards设置为一个空数组,即没有分片被分配。
- 如果
只有一个
group- 如果只有一个副本组,那么所有分片都被分配给这个唯一的组。
Groups数量少于或等于Shards数量如果副本组的数量少于或等于分片数(
NShards),那么每个组平均分配分片。具体来说,先计算每个组应该拥有的平均分片数(
avg),并计算剩余分片数otherShardsCount。这里使用一个循环对每个组进行分片分配,并处理剩余分片的分配。
分配检查与调整:
- 如果
count等于avg,当前副本组的分配已经平均,无需更改。 - 如果
count大于avg且otherShardsCount为 0,需要减少该副本组的分片,使其等于avg。 - 如果
count大于avg且otherShardsCount大于0,首先减少到avg,然后根据额外的分片数进一步减少,并更新otherShardsCount。 - 如果
count小于avg,尝试为该副本组分配更多的分片,直到达到avg或没有可用的分片。
最后,如果有未分配的分片(即值为 0 的分片),则分配给最后一个处理的组(
lastGid)。- 如果
Groups数量大于Shards数量如果副本组的数量大于分片数,那么每个组最多分配一个分片,可能会有未使用的副本组。
首先,移除已经分配给多个分片的组,然后将未分配的分片分配给尚未获得分片的组。
Trick: 由于每个 shard master 的 raft 是各自进行均匀分片的,我们需要保证他们会得到一样的结果。
但是如果对配置的
Groupsmap进行foreach的遍历,由于1. Go 语言底层采用的是哈希查找表,并且使用链表解决哈希冲突;2. 当我们在遍历 map 时,并不是固定地从 0 号 bucket 开始遍历,每次都是从一个随机值序号的 bucket 开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历;3. map在扩容后会发生key位置的移动。所以遍历得到的顺序都是不一样的,不能在各个shardmaster raft中 保证一致。为了解决这一点 ,我的做法是map 中所有 key 取出来排序,搞了个有序的数组,然后通过遍历数组中有序的 key 来遍历 map 取 value。
1 | |
Part 4B: Sharded Key/Value Server
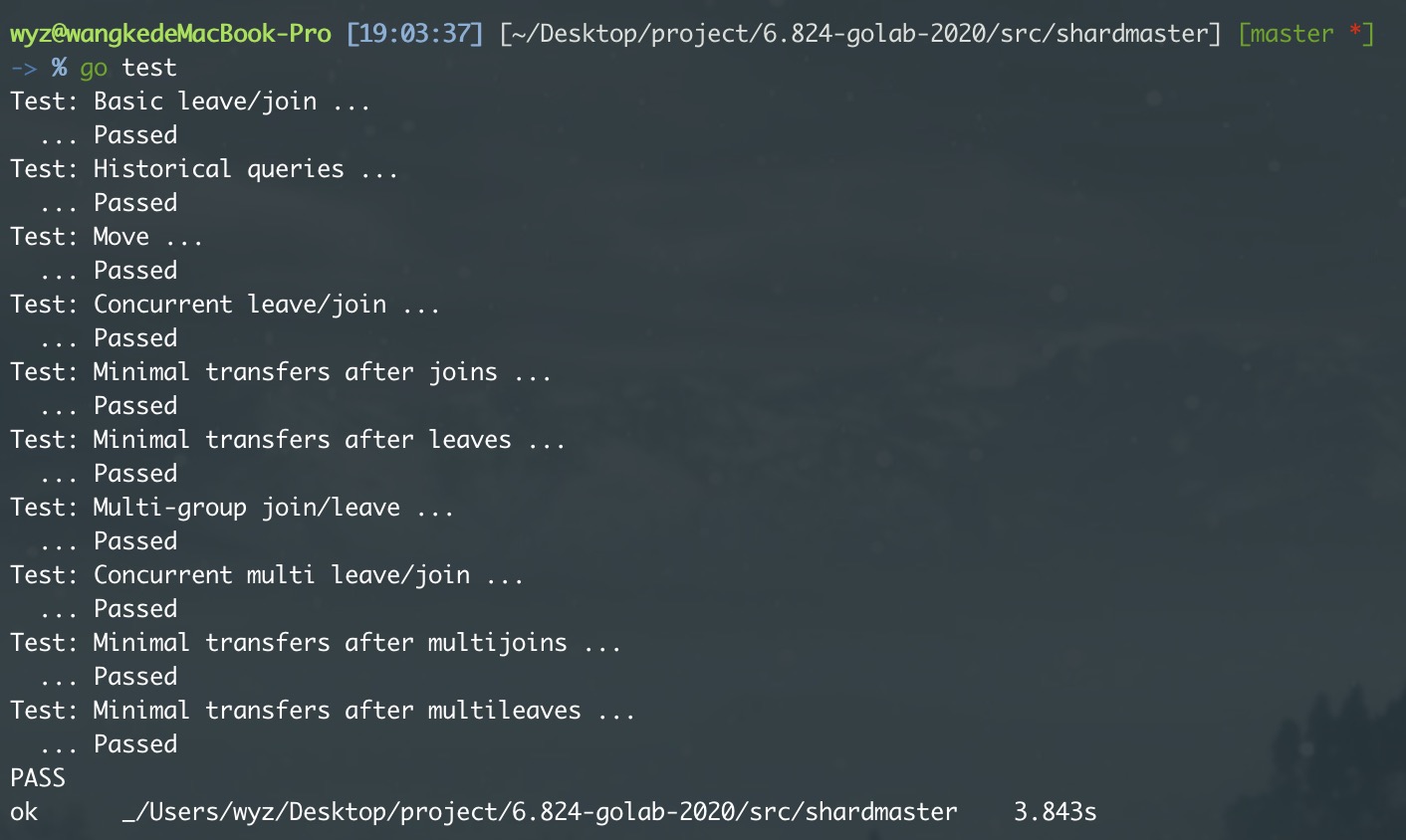
系统概览
系统的运行方式:一开始系统会创建一个 shard master 组来负责配置更新,分片分配等任务,接着系统会创建多个 raft 组来承载所有分片的读写任务。此外,raft 组增删,节点宕机,节点重启,网络分区等各种情况都可能会出现。
对于集群内部,我们需要保证所有分片能够较为均匀的分配在所有 raft 组上,还需要能够支持动态迁移和容错。
对于集群外部,我们需要向用户保证整个集群表现的像一个永远不会挂的单节点 KV 服务一样,即具有线性一致性。
- 客户端首先和
ShardMatser交互,获取最新的配置,根据最新配置找到对应key的shard,请求该shard的group。 - 服务端
ShardKVServer会创建多个raft组来承载所有分片的读写任务。 - 服务端
ShardKVServer需要定期和ShardMaster交互,保证更新到最新配置。 - 服务端
ShardKVServer需要根据最新配置完成配置更新,分片数据迁移,分片数据清理,空日志检测等功能。
客户端Clerk
客户端的请求逻辑大致如下:
- 使用
key2shard()去找到一个key对应哪个分片Shard; - 根据
Shard从当前配置config中获取gid; - 根据
gid从当前配置config中获取group信息; - 在
group循环查找leaderId,直到返回请求成功、ErrWrongGroup或整个 group 都遍历请求过; Query最新的配置,回到步骤1循环;
1 | |
拉取配置 pullConfig
每个 raft 组的 leader 需要有一个协程去向 ShardMatser 定时拉取最新配置,一旦拉取到就需要提交到该 raft 组中以更新配置。
1 | |
配置更新
kv层我们维护两个map,分别是记录 KVServer 目前持有的分片
以及 接受新配置后但是还未拉取的分片。
1 | |
ownShards表示 当前 raft 组在当前
config
下负责管理此分片,则该分片可以提供读写服务,否则该分片暂不可以提供读写服务,但不会阻塞配置更新协程拉取新配置。
waitShards表示当前 raft 组在当前
config 下负责管理此分片,暂不可以提供读写服务,需要当前
raft 组从上一个配置该分片所属 raft
组拉数据过来之后才可以提供读写服务。
historyShards 表示当前 raft 组在当前
config 下不负责管理此分片,不可以提供读写服务,但当前
raft 组在上一个 config
时复制管理此分片,因此当前 config 下负责管理此分片的
raft 组拉取完数据后会向本 raft
组发送分片清理的 rpc,接着本 raft
组将数据清空即可。
上一节中 拉取到新配置后,kv.rf.Start(config.Copy())
深拷贝一份 config 并提交到 raft 组进行 配置更新。
go kv.waitApplyCh()协程接收到新配置后,会经历以下过程:
遍历所有分片,根据新旧配置确定每个分片的状态变化:
如果新配置中的分片由当前副本组(
kv.gid)管理,且在旧配置中不是,那么它是新获得的分片(添加到newShardIds)。如果旧配置中的分片由当前副本组管理,但在新配置中不是,那么它是需要删除的分片(添加到
deleteShardIds)。同时记录当前副本组管理的所有分片(添加到ownShardIds)。
处理删除的分片
- 对于每个需要删除的分片,创建一个包含该分片数据的
MergeShardData结构,并添加到kv.historyShards中。这些数据将用于之后的分片迁移。 - 清空当前副本组中已删除分片的数据。
- 对于每个需要删除的分片,创建一个包含该分片数据的
更新副本组状态及配置,保存快照
更新当前副本组拥有的分片集合
kv.ownShards。如果旧配置的序号不为零,则更新需要等待的新分片集合
kv.waitShards。将新配置和旧配置分别复制到
kv.config和kv.oldConfig。调用
kv.saveSnapshot方法,保存当前状态的快照,以便在需要时恢复。
分片迁移
go kv.pullShards()协程用于分片迁移,我这边实现的的主动
pull 分片,当然也可以有 push 的实现。
抛出一个问题:这里为什么要单独启动一个协程来进行分片迁移呢?
pullShards()中
对于waitShards中的分片,分别启动 goroutine 来拉取分片。
此时,同样通过config.Groups[config.Shards[shardId]]找到所需分片所在的
raft 组(注意:此处的config是oldConfig),遍历这些 server
发起FetchShardData RPC
调用请求分片数据。FetchShardData RPC args 以及 reply
结构如下:
1 | |
收到成功 reply 之后,检查 waitShards 中是否还需要这个
shardId,且当前配置 (kv.config.Num)
是所请求配置的下一个版本(config.Num+1)。
这是为了确保这个分片的数据仍然属于这个raft组,并且配置没有再次变化。
如果条件满足,复制 RPC 响应数据到 mergeArgs
并记录日志。调用 Raft 的 Start 方法将合并的分片数据
(mergeArgs) 提交给 Raft 日志共识。如果当前节点不是领导者
(!isLeader),则终止处理。
1 | |
本 raft 组收到mergeArgs后check一下
ConfigNum (这也是旧的配置)以及
分片是否在waitShardIds中,并且根据Data和MsgIndexes更新
kv 数据以及 client对应的 msgId。这是出于 幂等性
的考虑。lastMsgIdx
需要用于isRepeated校验,防止执行重复请求。
1 | |
最后,本raft组向原分片所在raft组发送清理分片数据的 RPC调用。
分片清理
raft 组的 leader 收到分片数据的 RPC 后,前面的
historyShards就发挥完作用准备退休了。
leader 调用Start()方法将
CleanShardDataArgs结构的日志提交 raft 共识。
1 | |
各个 raft 组的节点 apply data清理任务,将historyShards
中 ConfigNum对应的分片删除,并保存快照。
1 | |
架构分析
为什么不在收到pullShard的请求之后就删除自己的shard?
我们需要考虑以下情况:假设 raft组 A 向 raft组B 发送 pullShard
请求,raft 组 B 删除了 shard 并 return RPC
请求,结果返回发送过程中网络断了,包含分片数据的MergeShardData就丢失了,这样就无法挽回了。
解决方案:我们在把 shard 数据发给 组B
后,暂时并不从自己这里删除(放入historyShards中),而由 组
A 确认自己已经收到数据并保存完毕(raft 达成共识)后,再告诉 组B
可以删除,相当于加入一个 删除确认机制。
处理配置更新的最简单方法是在转换完成之前禁止所有客户端操作。虽然概念上很简单,但这种方法在生产级系统中并不可行;每当机器被带入或取出时,这都会导致所有客户端长时间停顿。也就是说不能保证系统的 可用性。
假设某个 raft组 G3 在转换到 配置 C 时需要 G1 中的分片 S1 和 G2 中的分片 S2。如何使 G3 在收到必要的状态后立即开始为分片提供服务,即使它仍在等待其他一些分片?
有一个想法是:我们是否可以在 apply 协程更新配置的时候由 leader 异步启动对应的协程,让其独立的根据 raft 组为粒度拉取数据呢?
答案是不行的。可以想象一个这样的场景:leader apply 了新配置后便挂了,然后此时 follower 也 apply 了该配置但并不会启动该任务,在该 raft 组的新 leader 选出来后,该任务已经无法被执行了。
为了保证分片粒度的可用性,我的做法如下:
维护
ownShards,waitShards,historyShards三个map, 分别表示当前config下自己应该持有的分片、等待迁移的分片以及曾经拥有但还不该删除的分片。为了维持其间的幂等性,维护
lastMsgIdx[shardId][clientId]用来做重复校验。各个KVserver(除了leader)在 apply 分片迁移日志的时候更新自己的data。
另外也有许多网上的实现方法是
维护shard的状态state,而我交给KVserver对象使用map来管理这个状态,本质上没有区别。