CMU15-445 PROJECT4 Concurrency Control 项目记录
Overview
这个项目是关于在BusTub中添加对事务(transaction)的支持。
分为三个部分:
- Lock Manager:锁管理器,利用 2PL 实现并发控制。支持 REPEATABLE_READ、READ_COMMITTED 和 READ_UNCOMMITTED 三种隔离级别,支持 SHARED、EXCLUSIVE、INTENTION_SHARED、INTENTION_EXCLUSIVE 和 SHARED_INTENTION_EXCLUSIVE 五种锁,支持 table 和 row 两种锁粒度,支持锁升级。Project 4 重点部分。
- Deadlock Detection:死锁检测,运行在一个 background 线程,每间隔一定时间检测当前是否出现死锁,并挑选合适的事务将其 abort 以解开死锁。
- Concurrent Query Execution:修改之前实现的 SeqScan、Insert 和 Delete 算子,加上适当的锁以实现并发的查询。
Task #1 - Lock Manager
为了确保transaction操作的正确顺序,DBMS将使用一个锁管理器(LM)来控制事务何时被允许访问数据项。LM的基本概念是,它维护一个关于当前由活动事务持有的锁的内部数据结构。事务在被允许访问一个数据项之前,会向LM发出锁请求。LM会将锁授予调用的事务,阻止该事务,或中止该事务。
首先看一下lock manager的结构: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/** Structure that holds lock requests for a given table oid */
std::unordered_map<table_oid_t, std::shared_ptr<LockRequestQueue>> table_lock_map_;
/** Coordination */
std::mutex table_lock_map_latch_;
/** Structure that holds lock requests for a given RID */
std::unordered_map<RID, std::shared_ptr<LockRequestQueue>> row_lock_map_;
/** Coordination */
std::mutex row_lock_map_latch_;
std::atomic<bool> enable_cycle_detection_;
std::thread *cycle_detection_thread_;
/** Waits-for graph representation. */
std::unordered_map<txn_id_t, std::vector<txn_id_t>> waits_for_;
std::mutex waits_for_latch_;LockRequestQueue类:
1
2
3
4
5
6
7
8
9
10
11class LockRequestQueue {
public:
/** List of lock requests for the same resource (table or row) */
std::list<LockRequest *> request_queue_;
/** For notifying blocked transactions on this rid */
std::condition_variable cv_;
/** txn_id of an upgrading transaction (if any) */
txn_id_t upgrading_ = INVALID_TXN_ID;
/** coordination */
std::mutex latch_;
};
这里修改实际存放锁请求的队列为std::list<std::shared_ptr<LockRequest>> request_queue_;
Lock Manager 的作用是处理事务发送的锁请求,Lock Manager 对收到的请求进行处理。如果发现此时没有其他的锁与这个请求冲突,则授予锁并返回;如果存在冲突,例如其他事务持有这张表的 X 锁,则 Lock Manager 会阻塞此请求(即阻塞此事务),直到能够授予锁,再授予并返回。
Lock
一:检查 txn 的状态。
若 txn 处于 Abort/Commit 状态,抛逻辑异常; 若 txn 处于 Shrinking
状态,则需要检查 txn 的隔离级别和当前锁请求类型。三种隔离级别分别是: *
REPEATABLE _ READ: 事务可以持有获取所有类型的锁。所有锁只允许出现在
GROWING 状态。在Shrinking状态下不允许请求锁。此时造成事务终止,并抛出
LOCK_ON_SHRINKING 异常。 * READ _ COMMITTED:
事务可以持有获取所有类型的锁。所有锁都允许处于 GROWING 状态,只有 IS,S
锁允许处于 SHRINKING 状态。此时若为 IS,S 锁,则正常通过,否则抛
LOCK_ON_SHRINKING。 * READ_UNCOMMITTED: 事务只需要使用 IX、
X 锁。 GROWING 状态下可以持有X,IX 锁。 不允许使用S, IS, SIX锁。此时若为
IX,X 锁,抛 LOCK_ON_SHRINKING,否则抛
LOCK_SHARED_ON_READ_UNCOMMITTED。
若 txn 处于 Growing 状态,若隔离级别为 READ_UNCOMMITTED
且锁类型为 S/IS/SIX,抛
LOCK_SHARED_ON_READ_UNCOMMITTED。其余状态正常通过。
以LockTable()的READ_UNCOMMITTED隔离级别为例:
1
2
3
4
5
6
7
8
9
10
11
12if (txn->GetIsolationLevel() == IsolationLevel::READ_UNCOMMITTED) {
if (lock_mode == LockMode::SHARED || lock_mode == LockMode::INTENTION_SHARED ||
lock_mode == LockMode::SHARED_INTENTION_EXCLUSIVE) {
txn->SetState(TransactionState::ABORTED);
throw TransactionAbortException(txn->GetTransactionId(), AbortReason::LOCK_SHARED_ON_READ_UNCOMMITTED);
}
if (txn->GetState() == TransactionState::SHRINKING &&
(lock_mode == LockMode::EXCLUSIVE || lock_mode == LockMode::INTENTION_EXCLUSIVE)) {
txn->SetState(TransactionState::ABORTED);
throw TransactionAbortException(txn->GetTransactionId(), AbortReason::LOCK_ON_SHRINKING);
}
}
二:获取 table 对应的 lock request queue。
从 table_lock_map_ 中获取 table 对应的 lock request queue。注意需要对
map 加锁,并且为了提高并发性,在获取到 queue 之后立即释放 map 的锁。若
queue 不存在则创建。 1
2
3
4
5
6
7table_lock_map_latch_.lock();
if (table_lock_map_.find(oid) == table_lock_map_.end()) {
table_lock_map_.emplace(oid, std::make_shared<LockRequestQueue>());
}
auto lock_request_queue = table_lock_map_.find(oid)->second;
lock_request_queue->latch_.lock();
table_lock_map_latch_.unlock();
三:检查此锁请求是否为一次锁升级。
granted 和 waiting 的锁请求均放在同一个队列里,我们需要遍历队列查看有没有与当前事务 id 相同的请求。
首先,判断此前授予锁类型是否与当前请求锁类型相同,即幂等性检查。若相同,则代表是一次重复的请求,直接返回。否则进行下一步检查。
1
2
3
4if (request->lock_mode_ == lock_mode) {
lock_request_queue->latch_.unlock();
return true;
}
接下来,判断当前资源上是否有另一个事务正在尝试升级。若有,则终止当前事务,抛出
UPGRADE_CONFLICT
异常。因为不允许多个事务在同一资源上同时尝试锁升级(简化实现,否则需要增加一条升级队列)。
1
2
3
4
5if (lock_request_queue->upgrading_ != INVALID_TXN_ID) {
lock_request_queue->latch_.unlock();
txn->SetState(TransactionState::ABORTED);
throw TransactionAbortException(txn->GetTransactionId(), AbortReason::UPGRADE_CONFLICT);
}INCOMPATIBLE_UPGRADE 异常。 1
2
3
4
5
6
7
8
9
10
11
12if (!(request->lock_mode_ == LockMode::INTENTION_SHARED &&
(lock_mode == LockMode::SHARED || lock_mode == LockMode::EXCLUSIVE ||
lock_mode == LockMode::INTENTION_EXCLUSIVE || lock_mode == LockMode::SHARED_INTENTION_EXCLUSIVE)) &&
!(request->lock_mode_ == LockMode::SHARED &&
(lock_mode == LockMode::EXCLUSIVE || lock_mode == LockMode::SHARED_INTENTION_EXCLUSIVE)) &&
!(request->lock_mode_ == LockMode::INTENTION_EXCLUSIVE &&
(lock_mode == LockMode::EXCLUSIVE || lock_mode == LockMode::SHARED_INTENTION_EXCLUSIVE)) &&
!(request->lock_mode_ == LockMode::SHARED_INTENTION_EXCLUSIVE && (lock_mode == LockMode::EXCLUSIVE))) {
lock_request_queue->latch_.unlock();
txn->SetState(TransactionState::ABORTED);
throw TransactionAbortException(txn->GetTransactionId(), AbortReason::INCOMPATIBLE_UPGRADE);
}
锁升级大致步骤如下: 1. 判断是否能够升级; 2.
释放当前已经持有的锁,并在 queue 中标记正在尝试升级。 1
2lock_request_queue->request_queue_.insert(lr_iter, upgrade_lock_request);
lock_request_queue->upgrading_ = txn->GetTransactionId();1
2
3
4
5
6
7
8
9
10std::unique_lock<std::mutex> lock(lock_request_queue->latch_, std::adopt_lock);
while (!GrantLock(upgrade_lock_request, lock_request_queue)) {
lock_request_queue->cv_.wait(lock);
if (txn->GetState() == TransactionState::ABORTED) {
lock_request_queue->upgrading_ = INVALID_TXN_ID;
lock_request_queue->request_queue_.remove(upgrade_lock_request);
lock_request_queue->cv_.notify_all();
return false;
}
}
四:将锁请求加入请求队列。
使用智能指针创建一个lock_request,并加入队列尾部。
1
2auto lock_request = std::make_shared<LockRequest>(txn->GetTransactionId(), lock_mode, oid);
lock_request_queue->request_queue_.push_back(lock_request);
五:尝试获取锁。
和互斥锁、信号量类似,条件变量本质也是一个全局变量,它的功能是阻塞线程,直至接收到“条件成立”的信号后,被阻塞的线程才能继续执行。
条件变量与互斥锁配合使用。首先需要持有锁,并查看是否能够获取资源。这个锁与资源绑定,是用来保护资源的锁。若暂时无法获取资源,则调用条件变量的 wait 函数。调用 wait 函数后,latch 将自动释放,并且当前线程被挂起,以节省资源。这就是阻塞的过程。此外,允许有多个线程在 wait 同一个 latch。
当其他线程的活动使得资源状态发生改变时,需要调用条件遍历的
notify_all() 函数。notify_all()
会唤醒所有正在此条件变量上阻塞的线程。在线程被唤醒后,其仍处于 wait
函数中。在 wait 函数中尝试获取 latch。在成功获取 latch 后,退出 wait
函数,进入循环的判断条件,检查是否能获取资源。若仍不能获取资源,就继续进入
wait 阻塞,释放锁,挂起线程。若能获取资源,则退出循环。
1 | |
GrantLock() 中,Lock Manager
会判断是否可以满足当前锁请求。若可以满足,则返回
true,事务成功获取锁,并退出循环。若不能满足,则返回
false,事务暂时无法获取锁,在 wait
处阻塞,等待资源状态变化(即其他事务释放了锁)时被唤醒并再次判断是否能够获取锁。
row lock 与 table lock 几乎相同,仅多了一个检查步骤。在接收到 row lock 请求后,需要检查是否持有 row 对应的 table lock。必须先持有 table lock 再持有 row lock。
UnLock
一:获取对应的 lock request queue。
二:遍历请求队列,找到 unlock 对应的 granted 请求。
找到对应的请求后,根据事务的隔离级别和锁类型修改其状态。
三:在锁成功释放后,检查能够获取锁。
调用 cv_.notify_all() 唤醒所有阻塞在此 table 上的事务。
最后,Task1的核心是 条件变量阻塞模型。一个条件变量可以阻塞多个线程,这些线程会组成一个等待队列。当条件成立时,条件变量可以解除线程的“被阻塞状态”。也就是说,条件变量可以完成以下两项操作: * 阻塞线程,直至接收到“条件成立”的信号; * 向等待队列中的一个或所有线程发送“条件成立”的信号,解除它们的“被阻塞”状态。
为了避免多线程之间发生“抢夺资源”的问题,条件变量在使用过程中必须和一个互斥锁搭配使用。
Task #2 - Deadlock Detection
在阻塞过程中有可能会出现多个事务的循环等待,而循环等待会造成死锁。
首先构造waits_for_图。构建waits_for_图的过程是,遍历
table_lock_map_ 和 row_lock_map_
中所有的请求队列,对于每一个请求队列,用一个二重循环使用AddEdge()函数将所有满足等待关系的一对
tid 加入waits_for_图的边集。
1 | |
在成功构建 wait for
图后,对waits_for_图实施环检测算法。这里用dfs来实现环检测算法。
1 | |
本项目中HasCycle()需要在成环的节点中找到合适的事务终止之。挑选txn_id最大的事务终止即可。将此事务的状态设为
Aborted。并且在请求队列中移除此事务,释放其持有的锁,终止其正在阻塞的请求,并调用
cv_.notify_all()
通知正在阻塞的相关事务。此外,还需移除waits_for_图中与此事务有关的边。
最后,Task2的核心是
环检测算法。使用active_set_和safe_set_来记录已经过的节点和安全的节点。如果该节点通过邻接表经过所有路径都不会成环,则这个节点就是安全的,下次经过这个节点可以直接返回true;当深度遍历某节点时,先将其放入activate_set_中,如果在其邻接表中有active_set_中的tid,则表示有环,接着递归搜索。
Task #3 - Concurrent Query Execution
在并发查询执行期间,executor需要适当地锁定/解锁tuple,以实现相应事务中指定的隔离级别。
在这里我们需要更新 PROJECT3 中实现的一些
executor(SeqScan、Insert和Delete)的Next()方法。注意,当锁定/解锁失败时,事务应该中止。当执行器无法获得锁时,你应该抛出一个ExecutionException,这样执行引擎就会告诉用户,查询失败了,应该被中止。
SeqScan
如果隔离级别是READ_UNCOMMITTED
则无需加锁。加锁失败则抛出 ExecutionException 异常。这里
需要给表加 IS 锁,再给行加 S
锁。不能够直接给表加S/X锁,而是应该给表加意向锁,再给行加锁。
如果给表加 S锁的话,执行
DELETE... WHERE...的SQL语句,同一个 query
里先在下层SeqScan加了S锁,又尝试在Delete里加IX锁,但是S不能升级为IX,而导致query执行不了。
Insert & Delete
给表加IX锁,再给行加X锁即可。获取失败则抛
ExecutionException 异常。另外,这里的获取失败不仅是结果返回
false,还有可能是抛出了 TransactionAbort() 异常,例如
UPGRADE_CONFLICT,需要用 try catch 捕获。
Leaderboard Task (Optional)
Predicate pushdown to SeqScan.
可以在SeqScanExecutor中实现谓词过滤。将 SeqScan 算子上层的 Filter 算子结合进 SeqScan 里,这样仅需锁住符合 Predicate 的行。
Implement UpdateExecutor
实现 Update 算子,这样可以在原地直接修改 tuple,不需要先 Delete 再 Insert。表加 IX 锁,行加 X 锁。返回更新的行的数量。
Use Index
可以在表上创建一个索引,然后将谓词下推到IndexScanExecutor来做索引查询。例如,如果我们在id列上有一个索引,SELECT * WHERE id = 1可以(1)提取id = 1谓词
(2)在索引上直接调用GetValue(1),而不是做一个完整的索引扫描或表扫描。
具体做法是修改 IndexScan 算子,添加一种单点查询的情况。单点查询时IndexScan 算子中要注意加锁,表 IS 行 S。
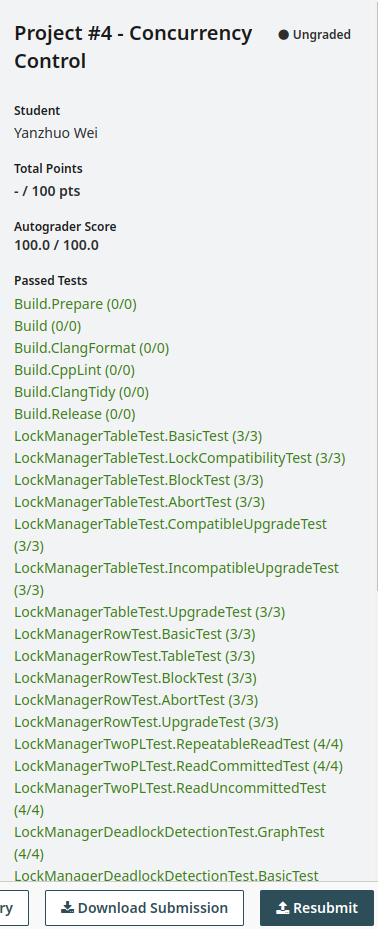
这次的成绩稍微差一点,但也不想花时间思考优化了。
update QPS 7.5 / count QPS 10.1
写在最后
经过将近一个月断断续续的摸爬滚打,可算把CMU15-445这项课程项目完成了。前两个项目更侧重于算法实现,后两个项目更多是对数据库相关概念知识的理解,虽然全部通过了,但是很容易遗忘,并且只追求速度做项目而没有仔细地过一遍课程加深理解。虽然完全pass了,但是还有些收尾工作应该完成,比如补完课程,有新的理解体会也会更新在博客上。